今週から Coursera の Big Data Analysis with Scala and Spark を受講している。その初回で出てきた "Why Scala? Why Spark?" に関する議論をざっくりとまとめる。(導入なので『RDDとは』みたいな話はしない)
Stack Overflow Developer Survey 2016 "Top Paying Tech in US" を見ると、なんと上位2つが Spark と Scala になっている:
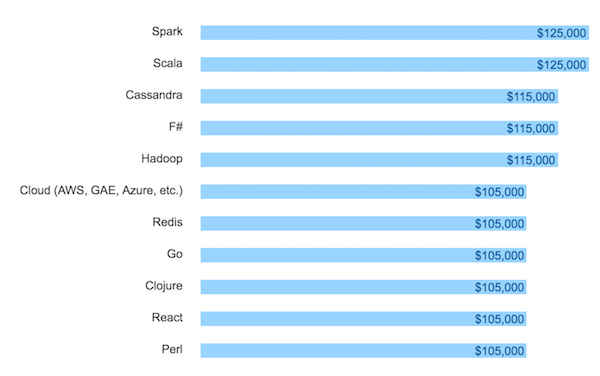
なぜこんなに人気なのか?
時はビッグデータ戦国時代、もちろん「大規模データを効率的に処理できるから」という事実が一因であることは言うまでもない。しかし、それ以上に強調すべき点がある。
Developer Productivity
Dr. Heather Miller いわく Scala, Spark を選択する理由は、それらが 開発者の生産性向上 に寄与するから。ここで言う開発者とは、並列分散環境下にあるビッグデータを処理する、何らかのコードを書く人々を指す。
実アプリケーションで Scala を選択するモチベーションとして、関数型パラダイムの恩恵を受けた豊富なコレクション操作 (e.g., reduce(), fold(), map(), filter()) とその表現力が挙げられると思う。
Spark上では(ほぼ)同一のインタフェースで分散データに対する処理が記述できる。これが重要。
シングルノードのときの通常のScalaコレクションに対する処理が
singleCollection.map(v => f(v))
だとすれば、同様の処理を Spark 上で書いても、それは
distributedData.map(v => f(v))
と書ける。ある大規模分散データに対して、まるでそれがローカルデータであるかのようにインタラクティブに処理を適用できる、これが Scala + Spark によって得られる生産性につながっているのだ。
データサイエンスとの親和性の高さ
ありがちな "小規模な" データサイエンス/解析業務は、R や Python, MATLAB で完結していた。アルゴリズム開発の段階ではそれで十分かもしれないが、それを実アプリケーションの上で実装しようとするとスケーラビリティが問題になる。つまり、いかに "大規模な" データサイエンスを実践するか、という話になる。
ここでポイントとなるのが、機械学習アルゴリズムの多くが イテレーション(ループ)を必要とする点。線形回帰であれニューラルネットワークであれ、パラメータを求めて、誤差を計算して、誤差を小さくするようにパラメータを少しだけ更新して、という処理を繰り返すことになる。
その点、通常のコレクション操作同様にコードが書ける Spark + Scala であれば恐れることは何も無い。
一方、Hadoop/MapReduce はどうだろうか。Map と Reduce というシンプルな API は魅力的だが、そのパラダイム上での各種機械学習アルゴリズムの実装は自明ではない。これはデータサイエンスをスケールさせる上で好ましいとは言えない。
レイテンシで Hadoop/MapReduce に勝る
僕らは大規模分散データを "効率的に" 処理したい。では、Spark と Hadoop/MapReduce はどちらが早いのか。このとき比較すべきは『耐障害性をどのように担保し、そのために必要な処理をどこで行っているのか』という点:
- インメモリの処理
- ディスクに対する処理(インメモリより100倍遅い)
- ネットワークを介した処理(インメモリより1,000,000倍遅い)
処理を行うノードの数が何百何千と増えたとき、当然途中のノードが死ぬ可能性は高くなる。そのとき、どのように処理を復帰させるのか。
Hadoop/MapReduce の場合、Map処理とReduce処理の間でデータをシャッフルして、中間データをディスクに書き出すことで潜在的な処理の失敗に備えている。このディスクに対する処理の時間的コストは大きい。
では Scala + Spark はどうか。このとき僕らは関数型パラダイムの恩恵を受け、データを immutable かつインメモリで処理することができる。つまり様々なデータ操作が、immutable なデータに対する変換操作のチェインで書ける。Spark は、仮にどこかのノードが死んだら対象データに対してそれらの変換操作を再実行すればよい、というアイディアで耐障害性を担保している。中間データのディスク書き出しなどは存在せず、すべてがインメモリで完結する。結果として、避けて通れないネットワークを介した処理も Spark のほうが少なく抑えることができる。
Sparkのホームページのトップでは、Spark が Hadoop より遥かに早くロジスティック回帰を処理できると言っている。詳細は "Apache Spark: A Delight for Developers" に書かれていて、イテレーションあたりの処理時間を比較するとその差は歴然:
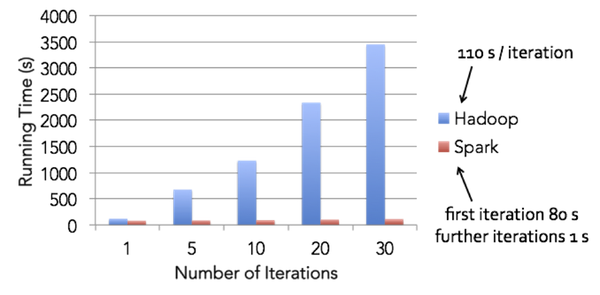
(Apache Spark: A Delight for Developers より引用)
イテレーションあたりの時間、つまり学習に要する時間が短いということは、同じ時間でもたくさんトライ&エラーができるということで、やっぱり Spark + Scala は生産的だ、というのがこのコースの導入部分での結論。
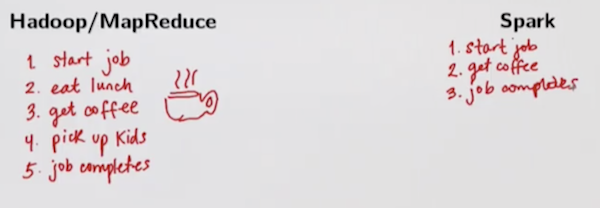
▲ 先生の「Hadoopでは半日待ってやっと処理が終わるけど、Sparkだとコーヒー淹れてる間に同じ処理ができるね」という微妙な例え。
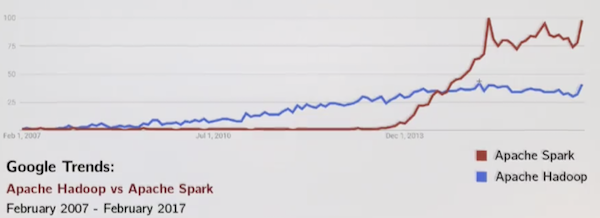
▲ そんな背景から、Google Trend ではもう Spark の圧勝という感じ。
まとめ
データサイエンスをスケールさせる上で、Spark は僕らの生産性を高めてくれる最高のソリューション(超意訳)。
サポートする
一杯のコーヒーを贈るカテゴリ
あわせて読みたい
- 2017年12月22日
- "Dynamo-style" に学ぶ Replication, Partitioning, Consistent Hashing の気持ち
- 2017年10月28日
- Courseraの"Functional Programming in Scala Specialization"を修了した
- 2017年5月14日
- 推薦システムのためのOSSたち
書いた人: Takuya Kitazawa(たくち)
長野県出身、カナダの首都・オタワを拠点に活動する技術者です。10年以上にわたりB2B/B2Cの各領域でWeb技術・データサイエンス・機械学習のプロダクト化および顧客への導入支援・コンサルティングに携わってきました。現在は独立し、アフリカ・アジア・北米の企業や個人を対象に、テクノロジー戦略の策定・実装をお手伝いしています。アフリカのマラウイでは現地企業のICTディレクターとして、デジタル・トランスフォーメーションを推進。ご意見・ご感想およびお仕事のご相談は [email protected] まで。
近況免責事項
- Amazonのアソシエイトとして、当サイトは amazon.co.jp 上の適格販売により収入を得ています。
- 当サイトおよび関連するメディア上での発言はすべて私個人の見解であり、所属する(あるいは過去に所属した)組織のいかなる見解を代表するものでもありません。
- Grammarlyによる外国語文章の校正を除き、ブログの執筆にあたり一切の生成AIを使用しておりません。
- 当サイトのコンテンツ・情報につきまして、可能な限り正確な情報を掲載するよう努めておりますが、個人ブログという性質上、誤情報や客観性を欠いた意見が入り込んでいることもございます。いかなる場合でも、当サイトおよびリンク先に掲載された内容によって生じた損害等の一切の責任を負いかねますのでご了承ください。
- その他、記事の内容や掲載画像などに問題がございましたら、直接メールでご連絡ください。確認の後、対応させていただきます。