IEEE Internet Computingの2017年5・6月号に "Two Decades of Recommender Systems at Amazon.com" という記事が掲載された。
2003年に同誌に掲載されたレポート "Amazon.com Recommendations: Item-to-Item Collaborative Filtering" が Test of Time、つまり『時代が証明したで賞』を受賞したことをうけての特別記事らしい 1。

「この商品を買った人はこんな商品も買っています」という推薦で有名なAmazonが1998年にその土台となるアルゴリズムの特許を出願してから20年、彼らが
- 推薦アルゴリズムをどのような視点で改良してきたのか
- 今、どのような未来を想像するのか
その一端を知ることができる記事だった。
アイテムベース協調フィルタリング
20年前も現在も、Amazonの推薦を支えているアルゴリズムは アイテムベースの協調フィルタリング だ。
協調フィルタリング (Collaborative Filtering; CF) とは、
- 履歴に基づいてユーザ/アイテム間の類似度を計算して、
- 「あなたと似ている人が買ったアイテム」や「今閲覧しているアイテムと似ているアイテム」を推薦する
という手法で 2、たとえばレーティングを元にユーザ間・アイテム間の類似度を計算するなら次のようなイメージになる:
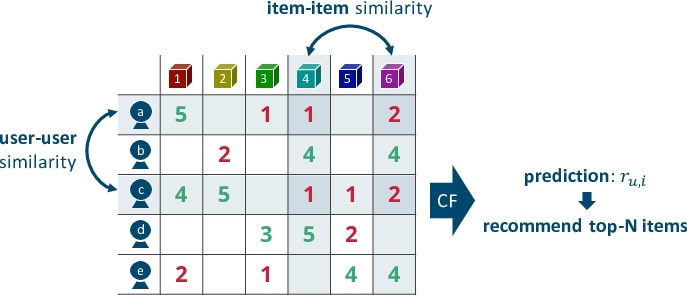
特に、実サービスの上では、
- ユーザ
- 総数が物凄いスピードで 増え続ける
- 一人ひとりの嗜好は 日々変動する
- アイテム
- ユーザ数に比べるとはるかに 少ない
- 「一緒に買われる傾向」のようなものはある程度 普遍的なもの
といった特徴から、アイテム間の類似度を利用した協調フィルタリング、すなわち「今閲覧しているアイテムと似ているアイテム」の推薦が精度、スケーラビリティ、計算効率などの面で好まれる。これが アイテムベースの 協調フィルタリング。
今回『時代が証明したで賞』を受賞した記事は、まさにAmazonがこのアイテムベース協調フィルタリングについて書いたものである 3。
一企業が実サービス上での推薦アルゴリズムについて公表したこの記事のインパクトは計り知れず、今や多くの有名サービスが類似アルゴリズムを実装している。そして、Microsoft ResearchいわくAmazonのページビューの3割は推薦によるものであり[1]、Netflixがストリーミングしている動画の再生時間の8割もまた推薦によってもたらされている[2] 4 らしい。
Amazonというサービスの20年前と現在の最大の違いは、扱っている商品の種類にある。創業当時のAmazonはインターネット書店だった。それが今では生活用品から衣類、PCまでなんでも買えてしまう。そのような変化の中で、Amazonはアイテムベース協調フィルタリングをどのように改良していったのだろうか。
“類似度”の定義
協調フィルタリングの本質は似ているユーザ/アイテムを見つけることにある。では、似ていることを測る指標・類似度をどのように定めるのか、という話になる。
『時代が証明したで賞』を受賞した記事を執筆した当時、彼らがサービスの裏側で行っていた処理は単純なものだった。それは、アイテム $X$ を購入したユーザのうち、どれだけのユーザがアイテム $Y$ も買ってくれるかという期待値 $E_{XY}$ を、
と計算する程度のものだったらしい。この期待値に基づいて「今閲覧しているアイテム ($X$) と似ているアイテム ($Y$)」を決定する。しかし 実際のユーザには各々にバイアス(購入傾向の偏り)があり、この単純なモデリングでは不十分だとすぐに気がついたという。
そこで、Amazonが2009年に出願した特許では「“誰が” $X$ を買ったのか」も加味した推定を行っている。それを雑に書くと:
こんな雰囲気。
たとえば「これまで $X$ しか買ったことがない!」という人がいれば、その人は $Y$ を買う見込みナシとして $E_{XY}$ には一切含まれない:
一方、$X$以外のアイテムを多く買っている人ほど、 $P(c \ \textrm{が}Y\textrm{を少なくとも一度は購入する})$ は1に近づく:
すなわちアイテム $Y$ を高確率で買ってくれるであろうユーザとして、1に近い値が $E_{XY}$ に加算されることになる。
さらに、これだけでは単に買ったユーザが多い 人気アイテムほど $E_{XY}$ が大きくなってしまう ので、最終的には実測値(実際に $X$ と $Y$ を両方買ったユーザの数)$N_{XY}$ を使って正規化しているとのこと:
- $N_{XY} - E_{XY}$
- $\frac{N_{XY} - E_{XY}}{E_{XY}}$
- $\frac{N_{XY} - E_{XY}}{\sqrt{E_{XY}}}$
・・・
このように、『似ているアイテム』を発見する方法には様々なバリエーションがあるが、万能なものは存在しない。No free lunchである。しかし同時に、“類似”アイテムを発見する適切な方法さえ設定できれば、シンプルな協調フィルタリングという手法が実データの上で非常にうまく動く 可能性がある。
うまく動いた例として、本稿では商品の互換性の問題を紹介している。
「このメモリカードはこのカメラで動作するのか?」
その質問に答えるためには、通常は人力での検証が不可欠だ。しかしデータが十分にあり、ひとたび類似度が適切に定められると、自然と互換性のあるアイテムが推薦上位にあがってきたらしい。アイテムに関する情報を一切与えずとも、ユーザの行動が暗にアイテムの互換性を示していたということだろう。面白い。
時系列の重要性
そのようなAmazon上で実際に観察された面白い傾向の中でも、ユーザの『閲覧』と『購入』のギャップ に関するものは、当たり前だけど特に重要な結果と言える。
いわく、本や音楽のような低価格なアイテムは閲覧したアイテムと購入したいアイテムが一致しやすい。ユーザは見たら見ただけ買ってくれる。一方、テレビのような高価なアイテムはたくさん閲覧しても、最終的に購入するのは1つだけなので、閲覧と購入の間にはギャップがある。
Amazon上でテレビをたくさん閲覧しても、最終的に購入するのは1つ。だとすれば、テレビ購入直後の推薦は特に大事にしたい。そのタイミングでは、テレビではなくBDプレーヤーなどのオプション商品を薦めるべきだ。
このような話から、ユーザの閲覧・購買行動の時系列を考慮することが重要な課題となる。
アイテムの傾向を見極める際も同様だ。『本を2冊購入した』という状況を例にとると、次のどちらのケースがより強く「この2冊は似ている」と言えるかは一目瞭然だろう:
- 最初に購入された本Aと、その数カ月後に購入された本B
- 同じ日に購入された本A, B
さらに、カメラの後にはSDカードが買われやすく、シリーズ物の漫画や小説は次巻が欲しくなるものだ。
そう、『時間的順序』は推薦において非常に重要な役割をはたす のだ。
時間という点では、新規ユーザへの推薦や、ライフサイクルの早いアイテム(例:アパレル商品)の推薦には cold-start 問題が付きまとう。限られた情報の中でいかにユーザの興味、アイテムの傾向を推薦に取り入れるか、というチャレンジがあり、ここには多くのヒューリスティクスが投入されているものと想像できる。
本稿では、
- 赤ちゃん商品を購入したユーザがいれば、その4年後には補助輪付きの自転車をオススメしてあげよう
- 本はまとめ買いの傾向があるので、一度購入したら次もしっかり関連した本を薦めよう
- 歯磨き粉のような消耗品は次の購入時期を見積もりやすいので、時期がきたらオススメしてあげよう
といった具体的なノウハウも紹介されていた。一体、こういうひとつひとつのルールをどうやって実装しているんだろうか…。
また、どの商品がユーザの興味をモデリングするために有意義なのか も考慮しなければならない。本やBDのようなメディア系コンテンツはユーザの興味を顕著に表す一方で、文房具のような汎用的な商品はユーザを特徴づけるとは言い難い。ホチキスを一度買っただけで文房具が大量に推薦されても困る。このバランスは難しい。
そして、ユーザの閲覧ログをみたときに「この人は絶対に新しいテレビを探しているな」と分かるのならテレビを推薦すべきだが、なにを探しているのか、なにが欲しいのか、モチベーションがよくわからないときは推薦の多様性、セレンディピティも忘れてはいけない。
このあたりのバランスはとても難しいので長期的な最適化が要求される。Amazonが実際にどのようなアーキテクチャ、更新頻度で推薦のモデルを組み立てているのか、もっと詳しく言及されていれば良かったけど、さすがに企業秘密か。
推薦の未来
本稿の最後には「推薦の未来、それは "Recommendations Everywhere" だ」と述べられている。
なお、Netflixも「これからは "Everything is a Recommendation" だ」と似たようなことを言っているが、これは少し意図が異なる。Netflix の言う "Everything" は、画面に表示されるコンポーネントのひとつひとつ、全てが推薦技術によってもたらされる という意味だ。
一方、本稿の言う "Everywhere" はもっと壮大な話で、サービスが自分のことを何でも知っていて、いたるところでパーソナライズされた情報が表示される という未来図。まぁわかりやすく言えば「これからはAIだ」である。
自分のあらゆる行動がパラメータに反映され、まるで友達のようにサービスが自分のことを詳しく知っている未来…と書いているけど、それはもう未来でも何でもなくて、Googleが実現している現在の話だよね、とも思った。
いずれにせよ、既に成熟しているかに思われたAmazonの推薦は、やっぱり今後もどんどん進化していくのだろう。Echoのような実世界デバイスからの情報を利用すればできることも増えるしね。
感想
Amazon = 協調フィルタリング の認識はあれど、「最新のアルゴリズムはどうなのか」についてはあまり表に出ていない印象だったので、抽象的ながらもこのような形でまとめて解説してくれたのは嬉しい。
個人的に一番大事にしていることは『情報推薦=機械学習ではない』という認識なので、シンプルな手法を真面目に考えて改良して、ヒューリスティクスとうまく付き合って生きている感がにじみ出ていた本稿には好感を抱く。もちろん細部では機械学習もしっかり取り入れているのだろうけど。
最近はindustryの推薦システムといえばNetflix、という風潮だけど、Amazonもこれを機にもっと詳細をいろいろ発表してくれないかな〜と思ったり。
1. ちなみに、たとえば国際会議WWWでは2015年にGoogleのPageRank論文に『時代が証明したで賞』を授与している。 ↩
2. 詳細は『【実践 機械学習】レコメンデーションをシンプルに、賢く実現するための3か条』『Courseraの推薦システムのコースを修了した』などを参照してください。 ↩
3. 『協調フィルタリング』という表現は似たようなアルゴリズムの総称なので、この手法の考案者がAmazonというわけではない。アイテムベースなら "Item-based collaborative filtering recommendation algorithms" あたりがオリジナルかな。 ↩
4. まぁ検索経由でNetflixの動画にたどり着くというシナリオがそもそも想像しづらいけど…。そしてNetflixは画面のすべてを“推薦”とみなしている節があるので、「8割が推薦経由!」と言われてもそれほど驚く数字ではない。 ↩
サポートする
一杯のコーヒーを贈るカテゴリ
あわせて読みたい
- 2021年11月17日
- もしも推薦システムの精度と多様性が単一の指標で測れたら
- 2017年2月18日
- "SLIM: Sparse Linear Methods for Top-N Recommender Systems"を読んだ
- 2017年1月27日
- Courseraの推薦システムのコースを修了した
書いた人: Takuya Kitazawa(たくち)
長野県出身、カナダの首都・オタワを拠点に活動する技術者です。10年以上にわたりB2B/B2Cの各領域でWeb技術・データサイエンス・機械学習のプロダクト化および顧客への導入支援・コンサルティングに携わってきました。現在は独立し、アフリカ・アジア・北米の企業や個人を対象に、テクノロジー戦略の策定・実装をお手伝いしています。アフリカのマラウイでは現地企業のICTディレクターとして、デジタル・トランスフォーメーションを推進。ご意見・ご感想およびお仕事のご相談は [email protected] まで。
近況免責事項
- Amazonのアソシエイトとして、当サイトは amazon.co.jp 上の適格販売により収入を得ています。
- 当サイトおよび関連するメディア上での発言はすべて私個人の見解であり、所属する(あるいは過去に所属した)組織のいかなる見解を代表するものでもありません。
- GrammarlyおよびLanguageToolによる外国語文章の校正を除き、ブログの執筆にあたり一切の生成AIを使用しておりません。
- 当サイトのコンテンツ・情報につきまして、可能な限り正確な情報を掲載するよう努めておりますが、個人ブログという性質上、誤情報や客観性を欠いた意見が入り込んでいることもございます。いかなる場合でも、当サイトおよびリンク先に掲載された内容によって生じた損害等の一切の責任を負いかねますのでご了承ください。
- その他、記事の内容や掲載画像などに問題がございましたら、直接メールでご連絡ください。確認の後、対応させていただきます。