Matrix Factorizationよりも高い精度が出るという話をよく聞く Sparse Linear Method (SLIM) を提案した論文を読んだ。
- Xia Ning and George Karypis. SLIM: Sparse Linear Methods for Top-N Recommender Systems. ICDM 2011.
概要
- Top-N推薦を高速に行う Sparse Linear Method (SLIM) を提案する。
- ユーザ-アイテム行列 $A \in \mathbb{R}^{\textrm{\#user } \times \textrm{ \#item}}$ の未観測値を $\tilde{A} = AW$ のように補完する疎なアイテム-アイテム行列 $W \in \mathbb{R}^{\textrm{\#item } \times \textrm{ \#item}}$ を求める。
- L1+L2正則化つきの最適化問題をcoordinate descentで解けばよい。
- $W$ が疎なので行列積 $AW$ が高速に計算できて、結果的にTop-Nのアイテム推薦が高速になる。
問題
あるユーザにアイテムを推薦したいとき、そのユーザの未観測(例:未購入、未評価、未視聴)アイテムに対して何らかの “スコア” を与えて、上位N個のアイテムを「おすすめリスト」として提示するのが Top-N推薦 というタスク。
これを実現する手法は、近傍法ベースの手法とモデルベースの手法に大別できる。
近傍法ベースの手法は協調フィルタリングとも呼ばれ、特にアイテムベースの協調フィルタリングは類似度計算が比較的軽く効率的。しかし既知のデータにoverfitしてしまって、推薦精度は悪くなりがち。
一方、Matrix Factorization などのモデルベースの手法は近傍法と比較して推薦精度が良いことが知られている。しかしモデルの学習やスコアの計算には大規模な行列計算を要するため非効率である。
そこで高精度かつ効率的なTop-N推薦を実現する新たな手法として SLIM を提案する。
定式化
履歴に基づいて 1 もしくは何か正の値を要素にとるユーザ-アイテム行列 $A \in \mathbb{R}^{\textrm{\#user } \times \textrm{ \#item}}$ があったとき、未観測なユーザ-アイテムペア ($i$, $j$) の予測値 $\tilde{a}_{ij}$ を求めたい。
ここで、アイテム $j$ と他のアイテムの間の重みを表現する疎なベクトル $\mathbf{w}_j \in \mathbb{R}^{\textrm{\#item}}$ を考え、 $\tilde{a}_{ij} = \mathbf{a}^{\top}_i \mathbf{w}_j$ とする。( $\mathbf{a}^{\top}_i \in \mathbb{R}^{1 \times \textrm{ \#item}}$ は $A$ の第 $i$ 行)
つまり、
- ユーザ $i$ の全アイテムに対する履歴: $\mathbf{a}^{\top}_i \in \mathbb{R}^{1 \times \textrm{ \#item}}$
- アイテム $j$ の全アイテムに対する重み: $\mathbf{w}_j \in \mathbb{R}^{\textrm{\#item}}$
の積で未観測だった $a_{ij}$ を補完する。
というわけで、全アイテムの $\mathbf{w}_j$ を並べた行列 $W \in \mathbb{R}^{\textrm{\#item } \times \textrm{ \#item}}$ を考えると、
とかける。
実際の推薦は以下の手順で行う:
- 対象ユーザ $i$ の全アイテムに対する予測値(スコア)を計算する: $\mathbf{a}_i^{\top} W \in \mathbb{R}^{1\times \textrm{ \#item}}$
- 推薦候補のアイテムを予測値の降順でソートする
- 上位N個のアイテムを推薦する
$\mathbf{w}_j$ は疎なベクトルであることを仮定したので行列 $W$ も疎で、おかげで $\mathbf{a}_i^{\top} W$ が効率的に計算できるのがSLIMのウリ。
$W$ の学習
二乗損失を考えて、各アイテム $j$ について $\mathbf{w}_j$ を求めるために次の最小化問題を解く:
ただし $\mathbf{w}_j \geq \mathbf{0}$ かつ $w_{j,j} = 0$ (i.e., 自分自身の重みは0) で、$\beta, \lambda$ は正則化係数。
L1正則化で $\mathbf{w}_j$ を疎にして、L2正則化でoverfitを防ぐ。要するにElastic Net。この問題はcoordinate descentで解くことができて、そのアルゴリズムは次の論文が詳しい:
- Jerome Friedman, Trevor Hastie, and Rob Tibshirani. Regularization Paths for Generalized Linear Models via Coordinate Descent. Journal of Statistical Software 33 (1), 2010.
SLIMの定式化のいいところは、アイテム $j$ ごとに問題が独立していて並列化が容易である点。
しかし欠点もあって、$A\mathbf{w}_j$ の存在からお察しの通り、coordinate descentで素直に実装すると1アイテムにつき (アイテム数 - 1)×(ユーザ数)回 のループが必要で重い。(無視できる1回は $w_{j,j}=0$ より)
そこで、特徴選択(=列のサンプリング)による学習の効率化も検討されている。あるアイテム $j$ の重みベクトル $\mathbf{w}_j$ を更新するときに、$A$ のすべての列を考えず、サンプリングした $k$ 本の列だけを考える ($k \leq \textrm{\#item}$) 。サンプリング方法はいろいろ考えられるけど、この論文では特にアイテム間類似度に基づく方法を試している。
具体的には、協調フィルタリングのように事前に各アイテムペアについて類似度を計算しておく。そして、$\mathbf{w}_j$ を計算するときには、アイテム $j$ との類似度が大きい $k$ 個のアイテムに対応する列だけを $A$ からサンプリングして考える。
評価
ユーザ-アイテム行列 $A$ は0/1(例:クリックした/してない、買った/買ってない)でも実測値(例:評価値、視聴回数)でも、どちらでも良い。実験では両方のパターンでTop−N推薦のパフォーマンスを評価している。
まずは二値データの場合。このとき本来実測値からなるデータは事前に二値化して使う。例として、Netflixの映画の評価値データを二値化したものでTop-N推薦を行った結果が以下(論文の表2を編集):
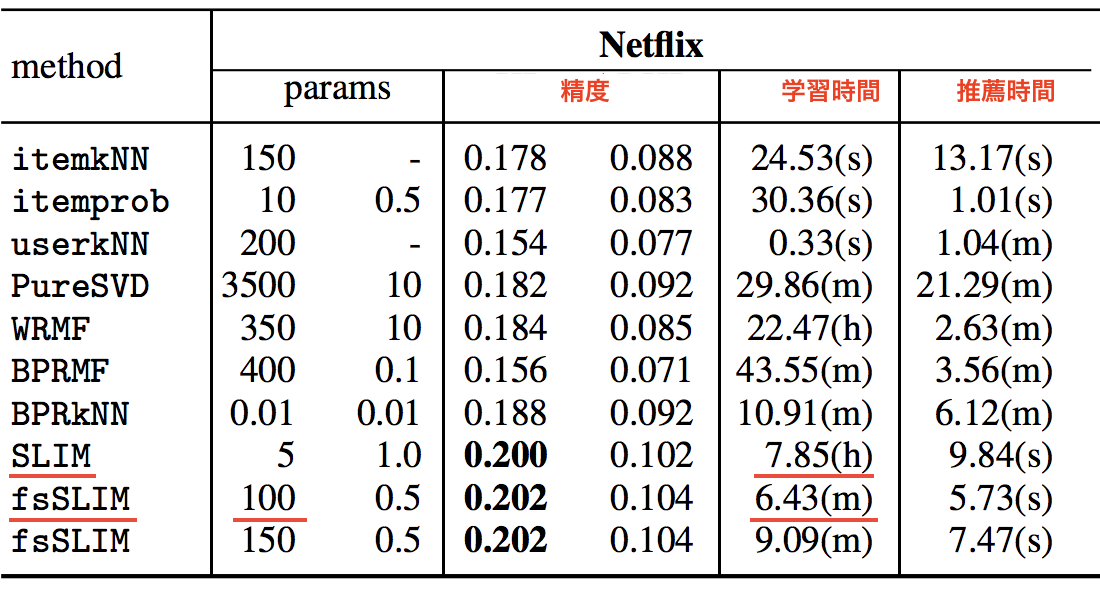
協調フィルタリング (*-kNN) やMatrix Factorization (*-MF) と比較して高い推薦精度を出しつつ、推薦にかかる時間は数秒台に抑えられており効率的。当初の狙い通りと言える。
ここで注目すべきは学習にかかる時間。疎行列を扱っているとはいえ、先述の通り実装はアイテム数×アイテム数×ユーザ数のオーダーになるので、普通のSLIMだと約8時間かかってしまう。しかし列のサンプリングを行えば (fsSLIM)、たとえば各アイテムにつき $k=100$ で $A$ の列をサンプリングすると学習時間が6分程度まで短縮できて、かつ精度は維持できる。サンプリング重要。
同様に、実測値データの場合もSLIMの精度が他手法を上回ることが示された。しかしこちらは実行時間に関する言及がない。二値データよりも実測値データの方が行列は密なはずなので、おそらく先の表以上の学習時間を要したのだとは思うけど。
まとめ
アイテムごとに独立した疎な重みベクトルを考えることでTop-N推薦を効率化する手法 SLIM について調べた。
機械学習の文脈ではすごく当たり前のことをやっているように見えるんだけど、こんなことでも情報推薦という応用分野においては新規性になりうるのであります。
SLIMの疎な出力はモデルの解釈という点で見ても嬉しいと思う。"Explanation in Recommender Systems" は重要なテーマ。
そして冒頭でも書いた通り、どうやら実際に試してみると多くのケースで定番のMatrix Factorizationよりも良い精度が出るらしい。しかし具体的に何が精度向上に寄与しているのか。そこがイマイチつかめなかった。
SLIMのまともな実装としては、 MyMediaLite と LibRec が挙げられる。前者は二値の行列のみに対応しており、後者ではそのような縛りはない。なおMyMediaLiteでは二乗損失だけでなくランキング損失(BPR)によるSLIMの実装も提供している。
サポートする
一杯のコーヒーを贈るカテゴリ
あわせて読みたい
- 2021年11月17日
- もしも推薦システムの精度と多様性が単一の指標で測れたら
- 2017年6月10日
- Amazonの推薦システムの20年
- 2017年1月27日
- Courseraの推薦システムのコースを修了した
書いた人: Takuya Kitazawa(たくち)
長野県出身、カナダの首都・オタワを拠点に活動する技術者です。10年以上にわたりB2B/B2Cの各領域でWeb技術・データサイエンス・機械学習のプロダクト化および顧客への導入支援・コンサルティングに携わってきました。現在は独立し、アフリカ・アジア・北米の企業や個人を対象に、テクノロジー戦略の策定・実装をお手伝いしています。アフリカのマラウイでは現地企業のICTディレクターとして、デジタル・トランスフォーメーションを推進。ご意見・ご感想およびお仕事のご相談は [email protected] まで。
近況免責事項
- Amazonのアソシエイトとして、当サイトは amazon.co.jp 上の適格販売により収入を得ています。
- 当サイトおよび関連するメディア上での発言はすべて私個人の見解であり、所属する(あるいは過去に所属した)組織のいかなる見解を代表するものでもありません。
- Grammarlyによる外国語文章の校正を除き、ブログの執筆にあたり一切の生成AIを使用しておりません。
- 当サイトのコンテンツ・情報につきまして、可能な限り正確な情報を掲載するよう努めておりますが、個人ブログという性質上、誤情報や客観性を欠いた意見が入り込んでいることもございます。いかなる場合でも、当サイトおよびリンク先に掲載された内容によって生じた損害等の一切の責任を負いかねますのでご了承ください。
- その他、記事の内容や掲載画像などに問題がございましたら、直接メールでご連絡ください。確認の後、対応させていただきます。