『PyTorchのautogradと仲良くなりたい』でPyTorchに入門したので、応用例としてMatrix FactorizationをPyTorchで実装してみようね 1。
Matrix Factorization
Matrix Factorizationは以前『Courseraの推薦システムのコースを修了した』でも触れたとおり、ユーザ-アイテム間の $m \times n$ 行列を、ユーザの特徴を表す行列 $P \in \mathbb{R}^{m \times k}$ (user factors) とアイテムの特徴を表す行列 $Q \in \mathbb{R}^{n \times k}$ (item factors) に分解する:
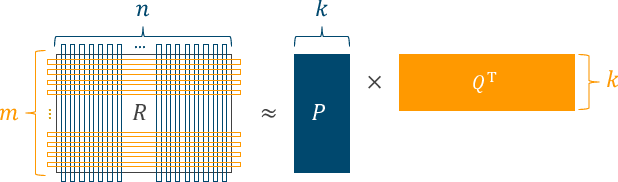
これを二乗損失のSGDで素直に実装すると、user_factors と item_factors の更新や評価値予測はこんな感じ:
import numpy as np
class MatrixFactorization(object):
def __init__(self, n_user, n_item, k=20, lr=1e-6, weight_decay=0.):
self.user_factors = np.random.rand(n_user, k)
self.item_factors = np.random.rand(n_item, k)
self.lr = lr
self.weight_decay = weight_decay
def predict(self, user, item):
return np.inner(self.user_factors[user], self.item_factors[item])
def __call__(self, user, item, rating):
err = rating - self.predict(user, item)
user_factor, item_factor = self.user_factors[user], self.item_factors[item]
next_user_factor = user_factor - self.lr * (-2. * (err * item_factor - self.weight_decay * user_factor))
next_item_factor = item_factor - self.lr * (-2. * (err * user_factor - self.weight_decay * item_factor))
self.user_factors[user], self.item_factors[item] = next_user_factor, next_item_factor
return err
PyTorchを意識して、__call__ で予測 predict(PyTorchの forward に相当)が呼ばれるようにした。あるユーザ・アイテムペアに対する予測値はその特徴を表すベクトルの内積で計算されて、それが predict。あと収束判定のために適当に err を返している。
Matrix Factorization in PyTorch
ではこれをPyTorchで実装するとどうなるか?
モデル本体は torch.nn.Module を継承して必要なパラメータを持たせた上で、予測関数 forward を定義すればよい:
from torch import nn
class MatrixFactorizationPyTorch(nn.Module):
def __init__(self, n_user, n_item, k=20):
super().__init__()
self.user_factors = nn.Embedding(n_user, k, sparse=True)
self.item_factors = nn.Embedding(n_item, k, sparse=True)
def forward(self, user, item):
# inner product of 1xN and 1xM tensors
return (self.user_factors(user) * self.item_factors(item)).sum(1)
モデルパラメータ(行列 $P, Q$)はPyTorchでどのように表現するのかというと、torch.nn.Embedding が正解。Embedding は各要素(ユーザやアイテム)を k 次元のベクトルで表現するもので、単語のベクトル表現を考える Word Embedding などで使われる。予測 forward は先ほどと同様に内積。
そしてPyTorch流に“二乗損失のSGD”を準備する:
from torch import optim
model = MatrixFactorizationPyTorch(n_user, n_item, k=20)
loss_function = nn.MSELoss()
optimizer = optim.SGD(model.parameters(), lr=1e-2)
SGDの学習率は 0.01 に設定して、正則化係数はデフォルト値の0.0で今回は無視。
いざ学習。
from torch import autograd
def as_long_tensor(val):
return torch.LongTensor([np.long(val)])
def as_float_tensor(val):
return torch.FloatTensor([np.long(val)])
last_accum_loss = float('inf')
for epoch in range(10): # 最大10反復
accum_loss = 0.
# 学習データのシャッフル
random.shuffle(samples_train)
for u, i, r in samples_train:
# PyTorchでは勾配は累積するのでサンプルごとに初期化
model.zero_grad()
# 入力値を `torch.Tensor` でラップして `autograd.Variable` 化
user = autograd.Variable(as_long_tensor(u)) # user index
item = autograd.Variable(as_long_tensor(i)) # item index
rating = autograd.Variable(as_float_tensor(r)) # target
# forward pass (prediction)
prediction = model(user, item)
# compute loss
loss = loss_function(prediction, rating)
accum_loss += loss.data[0]
# gradient of loss
loss.backward()
# update model parameters
optimizer.step()
print('MF (PyTorch)', epoch + 1, accum_loss)
if abs(accum_loss - last_accum_loss) < 1e-3: # 収束判定
break
last_accum_loss = accum_loss
(うーん、Bag-of-WordsのLogistic Regressionでもそうだったけど、やっぱり loss.backward() => optimizer.step() でパラメータが更新されるのが違和感…セマンティクスはすごく分かりやすいんだけど…。)
Lossの収束判定は、なにかいい関数が用意されていたりしないのかしら?
なにはともあれ、学習後はテスト用サンプルを forward に投げて評価してあげればよろしい:
accum_absolute_error, accum_squared_error = 0., 0.
for u, i, r in samples_test:
user = autograd.Variable(as_long_tensor(u))
item = autograd.Variable(as_long_tensor(i))
prediction = model(user, item)
accum_absolute_error += abs(prediction.data[0] - r)
accum_squared_error += (prediction.data[0] - r) ** 2
mae = accum_absolute_error / len(samples_test)
rmse = np.sqrt(accum_squared_error / len(samples_test))
logger.info('mf_pytorch : MAE = {}, RMSE = {}'.format(mae, rmse))
MovieLens100kデータセットで評価
torch.nn.MSELoss や torch.optim.SGD の内部実装が入り組んでいるので単純な比較はできないけど、 MatrixFactorization と MatrixFactorizationPyTorch をMovieLens100kデータセットに対して並列に走らせてみる:
from concurrent import futures
samples = load_ml100k()
n_user, n_item = 943, 1682
# 8:2 train/test splitting
random.shuffle(samples)
tail_train = int(len(samples) * 0.8)
samples_train = samples[:tail_train]
samples_test = samples[tail_train:]
with futures.ProcessPoolExecutor() as executor:
f1 = executor.submit(run_mf,
samples_train.copy(), samples_test.copy(),
n_user, n_item)
f2 = executor.submit(run_mf_pytorch,
samples_train.copy(), samples_test.copy(),
n_user, n_item)
f1.result()
f2.result()
(ちゃっかり concurrent.futures をつかう)
サンプルをランダムに 8:2 に分割して学習→評価した結果のログをベタ貼り:
2017-10-15 11:18:47,507 : 56939 : mf : start training
2017-10-15 11:18:47,562 : 56940 : mf_pytorch : start training
2017-10-15 11:18:48,678 : 56939 : mf : epoch = 1, accum. error = -45789.66409319061
2017-10-15 11:18:49,840 : 56939 : mf : epoch = 2, accum. error = -12041.007133098823
2017-10-15 11:18:50,960 : 56939 : mf : epoch = 3, accum. error = -6923.305935895317
2017-10-15 11:18:52,189 : 56939 : mf : epoch = 4, accum. error = -5214.0920045187595
2017-10-15 11:18:53,321 : 56939 : mf : epoch = 5, accum. error = -4122.734085365226
2017-10-15 11:18:54,488 : 56939 : mf : epoch = 6, accum. error = -3645.943440005198
2017-10-15 11:18:55,552 : 56939 : mf : epoch = 7, accum. error = -3095.084360349924
2017-10-15 11:18:56,579 : 56939 : mf : epoch = 8, accum. error = -2590.545763977188
2017-10-15 11:18:57,615 : 56939 : mf : epoch = 9, accum. error = -2264.0065333911293
2017-10-15 11:18:58,647 : 56939 : mf : epoch = 10, accum. error = -1896.1488359146224
2017-10-15 11:18:58,689 : 56939 : mf : MAE = 0.7915793587489275, RMSE = 1.004901038047285
2017-10-15 11:19:18,397 : 56940 : mf_pytorch : epoch = 1, accum. loss = 821542.0316947281
2017-10-15 11:19:48,678 : 56940 : mf_pytorch : epoch = 2, accum. loss = 111527.39108898955
2017-10-15 11:20:20,034 : 56940 : mf_pytorch : epoch = 3, accum. loss = 80923.26652375316
2017-10-15 11:20:49,565 : 56940 : mf_pytorch : epoch = 4, accum. loss = 70970.1188818557
2017-10-15 11:21:20,992 : 56940 : mf_pytorch : epoch = 5, accum. loss = 65501.150555915694
2017-10-15 11:21:51,124 : 56940 : mf_pytorch : epoch = 6, accum. loss = 61922.87653761433
2017-10-15 11:22:22,616 : 56940 : mf_pytorch : epoch = 7, accum. loss = 59274.52360257249
2017-10-15 11:22:53,081 : 56940 : mf_pytorch : epoch = 8, accum. loss = 56991.90325296985
2017-10-15 11:23:24,136 : 56940 : mf_pytorch : epoch = 9, accum. loss = 55083.32001617526
2017-10-15 11:23:54,136 : 56940 : mf_pytorch : epoch = 10, accum. loss = 53449.870972165234
2017-10-15 11:23:55,636 : 56940 : mf_pytorch : MAE = 0.9408608486979502, RMSE = 1.269512231434858
PyTorch遅ぇ! MatrixFactorizationPyTorch が1エポックを終えるよりも前に、MatrixFactorization は評価まで終了してしまう。手計算可能なシンプルな勾配を無理矢理 torch.autograd に計算させているのだから、当然といえば当然の結果か。それとも何か勘違いがあるのかな。このあたりは torch.nn や torch.optim をさらに詳しく見る必要がありそう。
精度はまぁこんなもんでしょう。
まとめ
ユーザ、アイテムの因子行列を torch.nn.Embedding で表現して、torch.optim.SGD と torch.nn.MSELoss を利用すればMatrix FactorizationもPyTorchで実装できた。この3点以外はBag-of-WordsのLogistic Regressionとほぼ変わらず。このようなコードフローの明解さがPyTorchの強みでもある。
ただ、これはあくまでPyTorchの“気持ち”を知るための一例に留めておくべきだろう。MFのようなシンプルなアルゴリズムにわざわざPyTorchを利用するのは、処理の過度なブラックボックス化という点において、あまり現実的ではないと思う。
とはいえ、少し設定(損失関数など)を変えれば発展的なMatrix Factorizationに化けたり、AdaGradやAdamのようなより良い最適化スキームをカジュアルに試せる点は魅力的である。このことは頭の片隅にしっかりおいておこう。
今回に使ったコードはこちら。
1. 先駆者がいたので大枠はそれに従っているけど、微妙なところもあったのでちょいちょい修正している。 ↩
サポートする
一杯のコーヒーを贈るカテゴリ
あわせて読みたい
- 2017年9月23日
- PyTorchのautogradと仲良くなりたい
- 2017年9月2日
- EuroSciPy 2017に参加してしゃべってきた
- 2017年1月27日
- Courseraの推薦システムのコースを修了した
書いた人: Takuya Kitazawa(たくち)
長野県出身、カナダの首都・オタワを拠点に活動する技術者です。10年以上にわたりB2B/B2Cの各領域でWeb技術・データサイエンス・機械学習のプロダクト化および顧客への導入支援・コンサルティングに携わってきました。現在は独立し、アフリカ・アジア・北米の企業や個人を対象に、テクノロジー戦略の策定・実装をお手伝いしています。アフリカのマラウイでは現地企業のICTディレクターとして、デジタル・トランスフォーメーションを推進。詳しい経歴はCV を参照ください。ご意見・ご感想およびお仕事のご相談は [email protected] まで。
近況免責事項
- Amazonのアソシエイトとして、当サイトは amazon.co.jp 上の適格販売により収入を得ています。
- 当サイトおよび関連するメディア上での発言はすべて私個人の見解であり、所属する(あるいは過去に所属した)組織のいかなる見解を代表するものでもありません。
- 当サイトのコンテンツ・情報につきまして、可能な限り正確な情報を掲載するよう努めておりますが、個人ブログという性質上、誤情報や客観性を欠いた意見が入り込んでいることもございます。いかなる場合でも、当サイトおよびリンク先に掲載された内容によって生じた損害等の一切の責任を負いかねますのでご了承ください。
- その他、記事の内容や掲載画像などに問題がございましたら、直接メールでご連絡ください。確認の後、対応させていただきます。