As I've been discussing over the last months, I personally believe measuring non-accuracy aspects of intelligent systems is one of the most important challenges to make algorithmic recommendations ethical.
- "Diversity" Means More Than What We Typically Think
- Validate, Validate, and Validate Data. But, in terms of what?
- Recommender Diversity is NOT Inversion of Similarity
Now, let's dive deep into the most ambiguous type of non-accuracy recommender metric: Serendipity.
By definition, we can say recommendation is serendipitous if and only if it's (1) relevant to a user AND (2) unexpected for them.
First, a serendipitous item should be not yet discovered and not be expected by the user [unexpected]; secondly, the item should also be interesting, relevant and useful to the user [relevant].
Source: "Beyond Accuracy: Evaluating Recommender Systems by Coverage and Serendipity" (2010)
Hence, the practitioners need to consider what defines relevance and unexpectedness of a recommended item, on a case-by-case basis. This is a big open-ended question, and that's why the concept of serendipity is rarely discussed both in academia and industry.
It should be noted that Serendipity is not the only metric that goes "beyond accuracy". For instance, Novelty and Diversity can also be employed to measure the goodness of recommendation as you can find at a dedicated section in the Recommender Systems Handbook.
Importantly, regardless of the measurements, capturing the user's taste/desire in the form of relevance is a must. That is, it is not a good idea to naively show random irrelevant contents without taking user-centricity into account for the novelty and diversity sake.
Meanwhile, novelty and diversity are essentially different from serendipity in terms of unexpectedness i.e., how "obvious" the recommendation is. Here is the citation from the "Beyond Accuracy" paper again:
[...] movie is then called novel recommendation instead of serendipitous recommendation because he might discover this movie by himself. [...] It is then called a diverse recommendation instead of a serendipitous recommendation as he might be not surprised about the recommendation.
- If the recommendation is novel, a user hasn't seen the content yet. However, they will eventually have an opportunity to interact with the item soon-ish, even if the recommender doesn't help anything.
- If the recommendation is diverse, it definitely helps users to break their unconscious bias and expand their "solution space", but the recommended items are still within the range of predictable outcomes.
Therefore, going beyond user's expectation is a unique, foundational requirement for serendipitous recommenders, and such a candidate must be in a tiny fraction of the entire relevant contents.
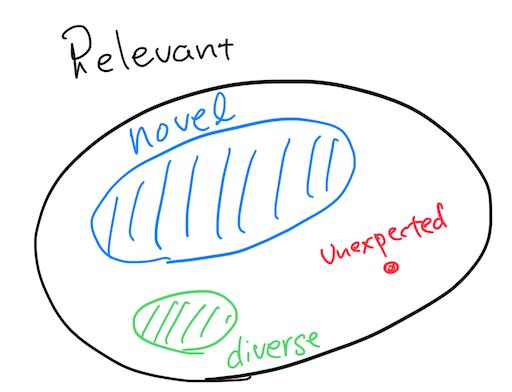
Notice that, since serendipitous recommendation makes users surprised, it's important to consider how to display the recommendation e.g., along with proper explanation. Otherwise, users would have no idea of what the recommendation is, and it unlikely becomes a positive "aha moment" for them.
Last but not least, there are several variations of the definition of serendipity and its relationship to the other metrics. To give an example, "A Survey of Serendipity in Recommender Systems" illustrates the problem spaces as follows, which extends the discussion to e.g., irrelevant unexpected items and familiar items that aren't new to a user.
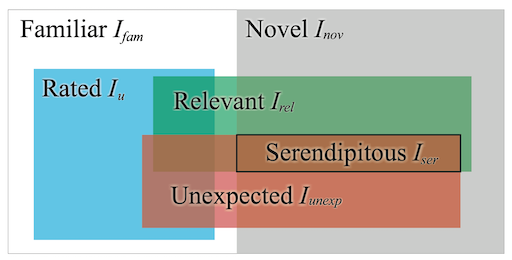
* Image source: Kotkov, et al. "A Survey of Serendipity in Recommender Systems" Fig. 1.
Support
Gift a cup of coffeeCategories
Data & Algorithms Recommender Systems
See also
- April 3, 2022
- Cross Validation for Recommender Systems in Julia
- February 27, 2022
- Recommender Diversity is NOT Inversion of Similarity
- July 15, 2021
- Reviewing Ethical Challenges in Recommender Systems
Author: Takuya Kitazawa
I am a product builder, mentor, and advocate for sustainable technology development with a decade of experience in AI/ML products, data systems, and digital transformation. Based in Canada and originally from Japan, I have lived and worked globally, including part-time residence in Malawi, Africa. Visit my portfolio to learn more about my work, or reach out to me at [email protected].
NowDisclaimer
- Opinions are my own and do not represent the views of organizations I am/was belonging to.
- I use Grammarly for correcting grammatical errors, but I do not rely on any other generative AI tools to create my blog content.
- I am doing my best to ensure the accuracy and fair use of the information. However, there might be some errors, outdated information, or biased subjective statements due to the nature of a personal website. Visitors understand the limitations and rely on any information at their own risk.
- If there are any issues with the content, please contact me so I can take the necessary action.