When it comes to building data-driven applications, evaluation matters. It matters A LOT, and an evaluation process is not always the same as how we calculate accuracy in the machine learning context (cf. Recommender Diversity is NOT Inversion of Similarity). Moreover, commonly speaking, online evaluation is the king to capture the unique characteristics of real-world events.
That said, it is still important to learn and leverage the basic offline evaluation techniques, so that developers can ensure a certain degree of validity of the implementation before production deployment. Thus, let's review what cross validation means for top-k item recommendation, and how the evaluation framework can be implemented in Julia, as part Recommendation.jl.
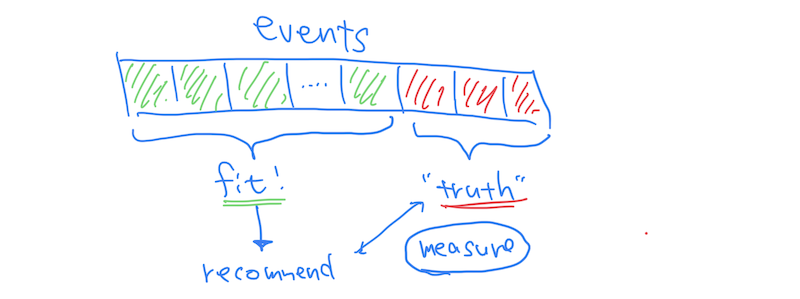
Assume we are trying to build and assess a top-k recommender based on a series of observed user-item events (e.g., click, purchase, rating). Here, a common approach is:
- splitting the entire dataset into two sub groups, like 80% of training and 20% of "ground truth" testing events;
- building a recommendation model based on the training data;
- generating top-k recommendations to users, and measuring the quality of recommendation in comparison with the test data.
A rough sketch of its Julia implementation would be:
(train_data, truth_data) = holdout(data) # (1)
recommender = Recommender(train_data, hyperparameters)
fit!(recommender) # (2)
evaluate(recommender, truth_data, metric(), topk) # (3)
where evaluate returns an average value of metric against truth_data over all users; recommender generates topk recommendation for every single user, and we measure its "goodness" by a certain metric.
evaluate(
recommender::Recommender,
truth_data::DataAccessor,
metric::RankingMetric,
topk::Integer
) -> Float64
To be more precise, we can see the process from a different angle by converting the list of events into a user-item matrix. Given training samples, we can construct a (sparse) matrix that represents observed events as non-zero elements—GREEN elements in the figure below.
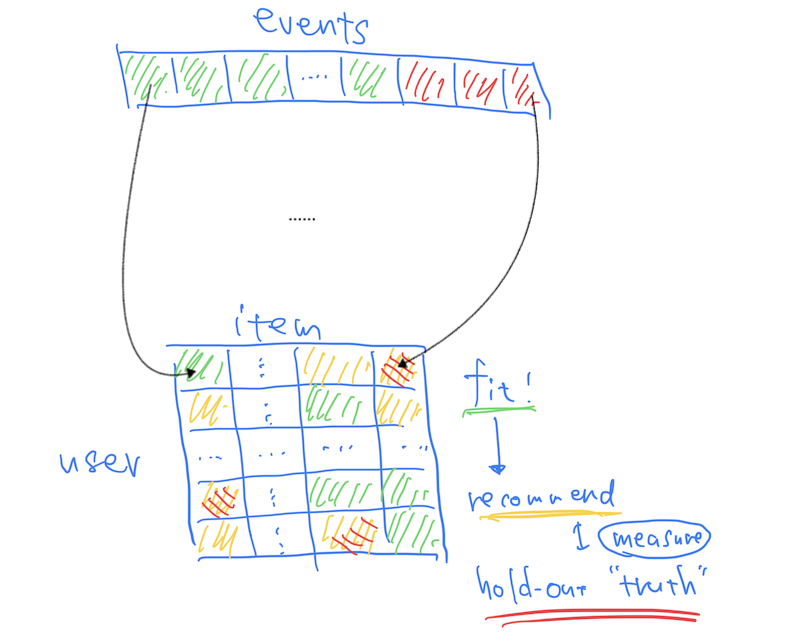
We then (1) simply build a recommender based on the training elements, (2) generate a per-user ranked list of recommended items from the elements that were unknown as of training—YELLOW—and (3) check how these ranks are aligned with the truth items that were intentionally omitted from the training—RED; from the accuracy standpoint, the RED truth items must be ranked relatively higher among the YELLOW recommendation candidates.
This is how holdout evaluation works for top-k recommendation; we extract a subset of events (elements) for testing. Eventually, a recommender assumes the holdout set is invisible when training and considers them as recommendation candidates.
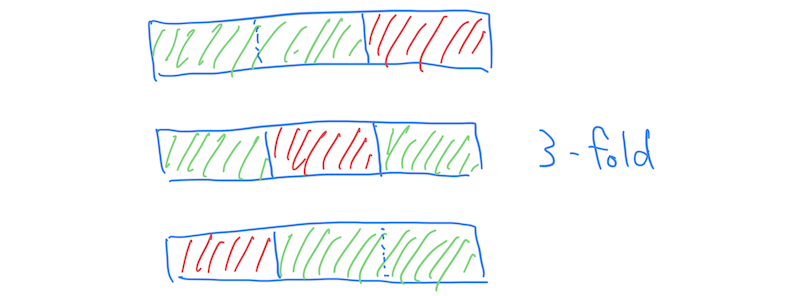
Cross validation basically repeats the holdout process over multiple different selection of testing samples. If we consider 3 distinct choices of test data, it is called 3-fold cross validation, which leaves 33.333% (100% / 3) of events for testing at a time and does the same for three times.
In Recommendation.jl, the cross validation method is implemented as:
function cross_validation(n_folds::Integer, metric::Type{<:RankingMetric},
topk::Integer, recommender_type::Type{<:Recommender},
data::DataAccessor, recommender_args...)
accum_accuracy = 0.0
for (train_data, truth_data) in split_events(data, n_folds)
recommender = recommender_type(train_data, recommender_args...)
fit!(recommender)
accum_accuracy += evaluate(recommender, truth_data, metric(), topk)
end
accum_accuracy / n_folds
end
where split_events returns n_folds pairs of train-test split. Nothing is special, but unlike per-item value/probability prediction that is common in machine learning, top-k recommendation needs to "predict" and evaluate a ranked list of items. The fact requires us to have a slightly different mindset in terms of what train/test data means.
Last but not least, there are several variations of the cross validation technique, and leave-one-out cross validation (LOOCV) is a special case of n-fold cross validation where n_folds equals to the number of all samples:
function leave_one_out(metric::Type{<:RankingMetric},
topk::Integer, recommender_type::Type{<:Recommender},
data::DataAccessor, recommender_args...)
cross_validation(length(data.events), metric, topk, recommender_type, data, recommender_args...)
end
Although LOOCV requires more repetition of the holdout process and is indeed computationally expensive, the evaluation method could be preferable for top-k recommendation to make sure a system constantly generates reasonable recommendation regardless of a choice of user and/or item.
- sklearn.model_selection.LeaveOneOut
- Evaluating Recommendation Systems — Part 2 | by Rakesh4real | Fnplus Club | Medium
- SLIM for fast top-k Recommendation · Hivemall User Manual
As a next step, what I personally want to explore more is cross validation with non-accuracy metrics, such as novelty, diversity, and serendipity. The development of Recommendation.jl continues towards the goal.
This article is part of the series: Building Recommender Systems in JuliaSupport
Gift a cup of coffeeCategories
Engineering Recommender Systems
See also
- October 14, 2022
- Ethics in Recommendation Pipeline—A First Look at RecSys 2022 Papers
- March 6, 2022
- Serendipity: It's Relevant AND Unexpected
- January 14, 2019
- Feeding User-Item Interactions to Python-Based Streaming Recommendation Engine via Faust
Author: Takuya Kitazawa
I am a product builder, mentor, and advocate for sustainable technology development with a decade of experience in AI/ML products, data systems, and digital transformation. Based in Canada and originally from Japan, I have lived and worked globally, including part-time residence in Malawi, Africa. Visit my portfolio to learn more about my work, or reach out to me at [email protected].
NowDisclaimer
- Opinions are my own and do not represent the views of organizations I am/was belonging to.
- I use Grammarly for correcting grammatical errors, but I do not rely on any other generative AI tools to create my blog content.
- I am doing my best to ensure the accuracy and fair use of the information. However, there might be some errors, outdated information, or biased subjective statements due to the nature of a personal website. Visitors understand the limitations and rely on any information at their own risk.
- If there are any issues with the content, please contact me so I can take the necessary action.