I recently found Microsoft's Recommenders repository is particularly useful to understand common discussion points when it comes to recommender systems. The motivation and brief history of the repository can be found in their paper "Microsoft Recommenders: Tools to Accelerate Developing Recommender Systems," which were demonstrated at RecSys 2019 and WWW 2020.
What I like about the repository can be three fold:
- High-quality, well-written Jupyter notebooks
- Minimal functionality on its PyPI package
- Consideration about non-accuracy metrics
High-quality, well-written Jupyter notebooks. Even though the repository contains an installable PyPI package recommenders (!), the most important part is a collection of well-written Jupyter notebooks that enable us to understand how to build recommender systems from data preparation and model training to evaluation and deployment.
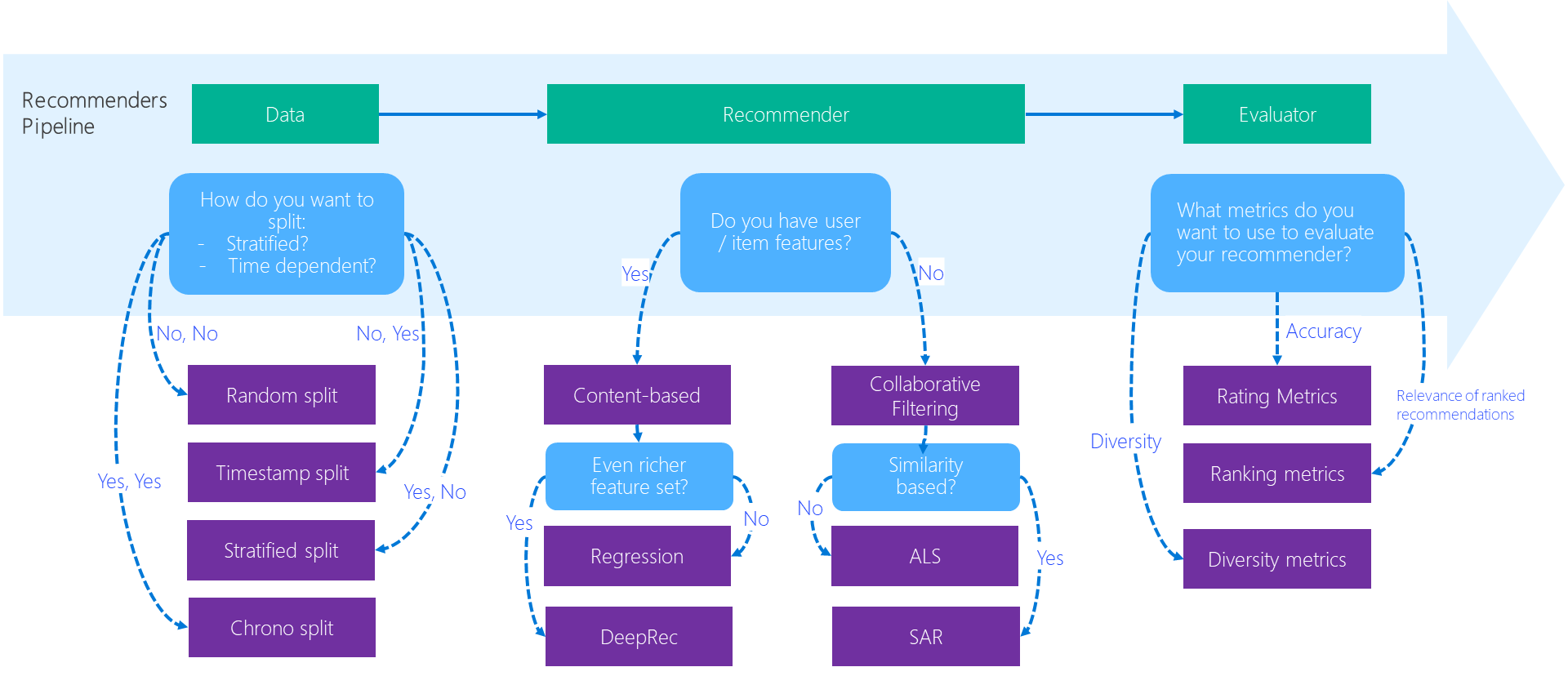 Source: recommenders/examples at main · microsoft/recommenders · GitHub
Source: recommenders/examples at main · microsoft/recommenders · GitHub
Importantly, the notebooks are not just for a series of code snippets + inline comments (like most of the repositories do) but for providing detailed texts/references so we can use the contents as "tutorial." Moreover, as mentioned in the paper, integration tests use papermill for validating the notebooks.
Minimal functionality on its PyPI package. Basically, the recommenders package itself is a set of utility functions that are widely applicable to a variety of scenarios, which makes the repository surprisingly minimal and useful; to avoid reinventing the wheel, the implementation of recommendation algorithms largely relies on the other packages such as PySpark and Surprise, while some minor ones are implemented from scratch (e.g., Restricted Boltzmann Machine).
Consideration about non-accuracy metrics. When we evaluate recommender systems, I cannot emphasize the importance of non-accuracy metrics enough as I wrote in Recommender Diversity is NOT Inversion of Similarity. The Recommenders repository is doing a great job in this regard since there is a dedicated notebook for explaining coverage, novelty, diversity, and serendipity metrics. I hope the package and repository evolve more around these topics moving forward.
Overall, I have an impression that Microsoft Recommenders nicely summarizes a good chunk of techniques every recommendation problems are commonly interested in; if there is someone who is completely new to recommender systems but familiar with Python-based data science & machine learning ecosystem, I'd first recommend to take a look at this repository. One potential area of improvement I can think of is around operationalizing recommenders. Currently, the examples are highly optimized for Azure-based deployment, which makes sense as the repository is owned by Microsoft, but it would be great if they could generalize the insights in a more OSS way.
Support
Gift a cup of coffeeCategories
Data & Algorithms Recommender Systems
See also
- February 27, 2022
- Recommender Diversity is NOT Inversion of Similarity
- July 15, 2021
- Reviewing Ethical Challenges in Recommender Systems
- January 21, 2017
- FluRS: A Python Library for Online Item Recommendation
Author: Takuya Kitazawa
I am a product builder, mentor, and advocate for sustainable technology development with a decade of experience in AI/ML products, data systems, and digital transformation. Based in Canada and originally from Japan, I have lived and worked globally, including part-time residence in Malawi, Africa. Visit my portfolio to learn more about my work, or reach out to me at [email protected].
NowDisclaimer
- Opinions are my own and do not represent the views of organizations I am/was belonging to.
- I use Grammarly for correcting grammatical errors, but I do not rely on any other generative AI tools to create my blog content.
- I am doing my best to ensure the accuracy and fair use of the information. However, there might be some errors, outdated information, or biased subjective statements due to the nature of a personal website. Visitors understand the limitations and rely on any information at their own risk.
- If there are any issues with the content, please contact me so I can take the necessary action.