Streaming recommendation is one of the most challenging topics in the field of recommender systems. The task requires recommendation engine to incrementally and promptly update recommendation model as new user-item interaction comes in to data streams (e.g., click, purchase, watch). I previously studied such incremental recommendation techniques, and eventually published a Python library named FluRS to make their implementation and evaluation easier.
As I described in my research paper a couple of years ago, incremental recommender systems run in three steps:
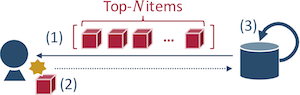
- System recommends top-N items to a user by using a production recommendation model
- User may interact with one or more recommended items
- Recommendation model is incrementally updated based on the observed user-item interactions
In order to provide an implementation idea of the above recommender systems, this article examines Faust, a handy stream and event processing engine for Python, in combination with FluRS. Faust allows our Python code to easily consume data streams and do something for incoming events.
pip install faust
Updating FluRS recommender from a Faust processor
Assume that a dummy Kafka topic flurs-events continuously receives MovieLens rating events represented by pairs of <user, item, rating, timestamp>. In case that those events are JSON-serialized, a Faust event processor can be defined as:
import json
import faust
app = faust.App(
'flurs-recommender',
broker='kafka://localhost:9092',
value_serializer='raw',
)
topic = app.topic('flurs-events', value_type=bytes)
@app.agent(topic)
async def process(stream):
async for obj in stream:
event = json.loads(obj)
# do something awesome
In Faust, the @app.agent(topic) decorator enables creating a processor, and what we have to do is just writing a Python function that does something for every single events from a stream. Since our application is a streaming recommender system, the function should update recommendation model against an observed event:
@app.agent(topic)
async def process(stream):
async for obj in stream:
event = json.loads(obj)
# focus only on positive feedback (i.e., rating is greater than 3)
if event['rating'] < 3:
continue
# user (item) index = event['user'] (event['item']) - 1
user, item = User(event['user'] - 1), Item(event['item'] - 1)
recommender.update(Event(user, item))
It should be noticed that this processor corresponds to Step 3 in the above figure of streaming recommendation.
On the latest version of FluRS, User, Item and Event classes wrap user/item instances with their indices and features. For instance, recommender can be a matrix factorization model that is preliminary initialized as follows:
from flurs.data.entity import User, Item, Event
from flurs.recommender import MFRecommender
recommender = MFRecommender(k=40)
recommender.initialize()
n_user, n_item = 943, 1682
for u in range(1, n_user + 1):
recommender.register(User(u - 1))
for i in range(1, n_item + 1):
recommender.register(Item(i - 1))
The code deterministically registers all possible instances to the recommender beforehand, since we already know total number of users and items (i.e., movies) in the public dataset.
Running the streaming recommendation engine
Eventually, our stream recommender, recommender.py, can be implemented and executed as:
from flurs.data.entity import User, Item, Event
from flurs.recommender import MFRecommender
import json
import faust
app = faust.App(
'flurs-recommender',
broker='kafka://localhost:9092',
value_serializer='raw',
)
topic = app.topic('flurs-events', value_type=bytes)
recommender = MFRecommender(k=40)
recommender.initialize()
n_user, n_item = 943, 1682
for u in range(1, n_user + 1):
recommender.register(User(u - 1))
for i in range(1, n_item + 1):
recommender.register(Item(i - 1))
@app.agent(topic)
async def process(stream):
async for obj in stream:
event = json.loads(obj)
if event['rating'] < 3:
continue
user, item = User(event['user'] - 1), Item(event['item'] - 1)
recommender.update(Event(user, item))
faust -A recommender worker -l info
Note that the easiest way to set up a local Kafka environment on Mac would be:
brew install zookeeper kafka
brew services start zookeeper
brew services start kafka
Producing MovieLens rating events to the Kafka topic
Here, the following code, producer.py, produces toy events to the dummy topic:
import sys
import json
from kafka import KafkaProducer
from kafka.errors import KafkaError
producer = KafkaProducer(
bootstrap_servers='localhost:9092',
value_serializer=lambda m: json.dumps(m).encode('ascii'))
topic = 'flurs-events'
keys = ['user', 'item', 'rating', 'timestamp']
with open(sys.argv[1], 'r') as f: # /path/to/ml-100k/u.data
for line in f.readlines():
event = dict(zip(keys, map(int, line.rstrip().split('\t'))))
future = producer.send(topic, event)
try:
future.get(timeout=10)
except KafkaError as e:
print(e)
break
python producer.py /path/to/ml-100k/u.data
The producer simulates Step 2 in the flow of incremental recommendation, where user-item interaction is observed and emitted to a core recommendation engine.
Finally, producer.py communicates with recommender.py via Kafka and Faust, and rating events are fed to the processor.
Observations
Thanks to the easy-to-use Python-based streaming processing engine, I was able to provide mock implementation of streaming recommender system by using FluRS. Below I list some open questions we need to consider more closely:
- How to deal with unknown total number of users and items
- We preliminary registered total number of users and items to initialize a recommender, but those numbers are normally unknown at the time of initialization in practice.
- How to choose appropriate serialization format
- JSON-serialization is not always the best choice.
- Event records passing through data streams should be as much as simple for efficiency.
- If we directly pass
flurs.data.entity.Eventobject to a stream, we need to implement a dedicated serializer and deserializer of the custom object.
- How to integrate recommendation logic
- Implementation of Step 1 in the above figure, where a recommendation model is hold and recommendation is actually conducted, is not obvious at this moment.
Based on these observations, I will improve the package to make it more feasible.
Support
Gift a cup of coffeeCategories
Engineering Recommender Systems
See also
- April 3, 2022
- Cross Validation for Recommender Systems in Julia
- March 6, 2022
- Serendipity: It's Relevant AND Unexpected
- January 21, 2017
- FluRS: A Python Library for Online Item Recommendation
Author: Takuya Kitazawa
I am an independent consultant, mentor, and advocate for sustainable technology development with a decade of experience in AI/ML products, data systems, and digital transformation. Based in Canada and originally from Japan, I have lived and worked globally, including part-time residence in Malawi, Africa. See CV for more information, or contact at [email protected].
NowDisclaimer
- Opinions are my own and do not represent the views of organizations I am/was belonging to.
- I am doing my best to ensure the accuracy and fair use of the information. However, there might be some errors, outdated information, or biased subjective statements because the main purpose of this blog is to jot down my personal thoughts as soon as possible before conducting an extensive investigation. Visitors understand the limitations and rely on any information at their own risk.
- That said, if there is any issue with the content, please contact me so I can take the necessary action.