Yahoo!がOSSとして開発している異常検知フレームワーク "EGADS" (Extensible Generic Anomaly Detection System) について書いた次の論文を読んだ:
リアルタイムなデータをモデリングする種のアルゴリズムの実装とはどうあるべきなのか、という話は難しい。
僕も異常検知や情報推薦のためのアルゴリズムをパッケージ化してみてはいるものの、
- 時系列データの入力、モデリング、予測、出力といったコンポーネントをいかに切り分けて実装するか
- バッチとオンラインアルゴリズムのバランスをいかに取るか
- どこまで自動化して、どこにヒューリスティクスを取り入れる余地を残すか
といった点は本当に悩ましい。その点、この論文は1つの事例としてとても示唆的で、学びの多いものだった。
概要
大規模な時系列データから自動的に異常を検知してくれる、汎用的かつスケーラブルなフレームワーク "EGADS" を開発した。これはYahoo!社内のモニタリングシステムの一部として実用されていて、複数データソースから流れ込む数百万の時系列データをさばいている。
昨今の異常検知システムは特定のユースケースに最適化されたものであることが多く、素直に応用すると必ず大量のFalse Positiveとスケーラビリティの問題に直面する。
その点EGADSはHadoopやStormを組み合わせた実践的、スケーラブルかつリアルタイムな異常検知システムであり、複数のアルゴリズム実装と機械学習による“異常”のフィルタリング機構によって幅広い応用が可能。
アーキテクチャ
EGADSは大きく分けて3つのコンポーネントから成る:
- Time-series modeling module (TMM)
- 時系列データをモデリングする
- Anomaly detection module (ADM)
- モデルに基づいて異常な入力データを検知する
- Alerting module (AM)
- 検知された異常なデータをフィルタリングして、“ユーザが着目している異常”についてのみアラートを発する
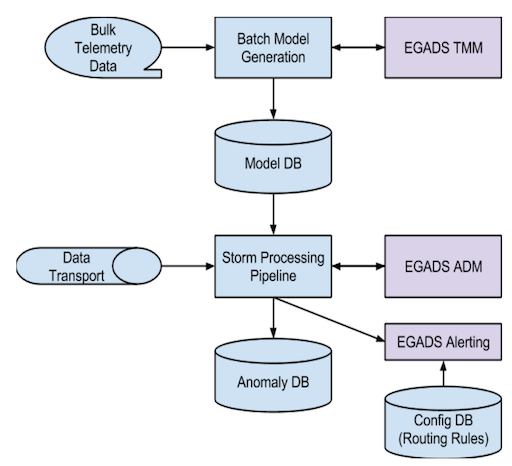
(原論文Fig. 1より)
- バッチ
- 観測した時系列データをHadoopクラスタ上で保持
- TMMが蓄積された観測データをバッチでモデリング
- モデルはModel DBに格納
- オンライン
- Stormでリアルタイムにデータを見る
- Model DBのモデルを使って観測したデータが異常か否かを検知するモジュール (ADM) をかませる
- 異常と判断されたデータはAMで更にフィルタリング、“ユーザが着目している異常”ならばアラート
このバッチとオンライン処理の切り分けから、『モデリングに関する計算は可能な限り事前に済ませておく』というスループット/スケーラビリティ向上に対する強い意思がうかがえる。
また、本文で言及されていることとして次のような視点もある:
- モデルはインメモリで保持したい
- 複数の類似する時系列データに対してモデルを共有すれば、余計なモデルを持たなくていい
- オンラインアルゴリズムを検討する
- モデルのWrite回数が増えるのは注意
- サイズ、学習時間、精度のトレードオフを常に意識する
異常検知アルゴリズム
EGADSは豊富な異常検知アルゴリズムを実装しているが、一口に“異常“と言ってもいくつかのタイプが存在する:
- タイプ1: Outlier(外れ値)
- モデルに基づく予測値から著しくかけ離れている観測点
- 手法1: plug-in method
- 正常な状態をモデリングして、そこからどれだけ外れているかをみる
- ARIMA, Exponential Smoothing, カルマンフィルタなど
- 「正常なら次の観測値はこれくらいのはず」という予測を機械学習的、もしくはルールベースに基づいて出力
- その結果をADMへ→観測値と予測値の相対誤差に対するthresholdingなどから異常を検知
- 正常な状態をモデリングして、そこからどれだけ外れているかをみる
- 手法2: decomposition-based
- 時系列データをトレンド、季節性、ノイズといったコンポーネントに分解する
- ノイズが通常よりも大きければそれは異常
- タイプ2: Change point(変化点)
- データの傾向がその前後で大きく異なる時刻
- Outlierとの違いは、Change-pointはもっと大域的かつ中長期的な変化を発見する点
- 手法としては、Kernel Density Estimationとか
- 変化点検知とは「ここまでに作ったモデルで観測データが説明できなくなるタイミング」を見極めることであり、つまり「変化」の定義はどのモデルを使うかに大きく依存する
- タイプ3: Anomalous time-series
- 他とは大きく異なる挙動を示す時系列
- 時系列データに対する特徴量 (e.g., trend, seasonality, auto-correlation) から、時系列をクラスタリング
- 各クラスタの中心値と観測した時系列の特徴量を比較して外れ時系列を発見
フィルタリング
最適な異常検知アルゴリズムとはユースケース(時系列データ)依存であり、万能なものは存在しない。なのでEGADSはOutlier, Change-point, Anomalous time-seriesのそれぞれを対象とする複数のアルゴリズムからの出力を集約、フィルタリングする。そして、本当に捉えたい異常に対してのみアラートを発することで、False Positiveの削減をねらう。
具体的には、与えられた時系列データに対してユーザが“異常”だと思った部分をマーキングできるインタフェースを提供しているという。このフィードバックとADMの出力ペアに対して『この異常はこのユーザが着目している異常か否か』の分類器を学習し、AMで異常のフィルターとしてつかう。分類器は、Yahoo!の場合はAdaBoost。
まとめ
バッチとオンライン処理を組み合わせた現実的なアーキテクチャには好感…というか、こうしないとproductionで実用可能なモノは作れないんだろうなぁ。アルゴリズム自体はオンラインなものも多いけれど、Stormのところでモデルの更新と異常の検知を同時にやっても、あまり嬉しいことは無さそう。
多角的に異常検知を行って、最後に人のフィードバックを取り入れたフィルタリング機構を挟む発想は「なるほど」と思った。すべてを自動化せず、人間が取捨選択する余地を残すこと―機械学習アプリケーション一般に言える、大切な考え方ですね。
なお、実験ではラベリング済みの人工データとYahoo!のユーザログインを集約した時系列のデータに対して、モデルのサイズ、学習時間、精度のトレードオフを確認している。異常検知アルゴリズムはRecallやPrecisionで精度評価して、時系列データの特徴に応じて最適なアルゴリズムが異なることを示している。だからこそ、EGADSは1つのフレームワーク上で複数のアルゴリズムを提供しているというわけだ。No free lunch!
サポートする
一杯のコーヒーを贈るカテゴリ
あわせて読みたい
- 2017年8月26日
- 異常検知のための未来予測:オウム返し的手法からHolt-Winters Methodまで
- 2017年7月16日
- Leakage in Data Mining
- 2016年10月4日
- Treasure Dataインターンにみる機械学習のリアル #td_intern
書いた人: Takuya Kitazawa(たくち)
長野県出身、カナダの首都・オタワを拠点に活動する技術者です。10年以上にわたりB2B/B2Cの各領域でWeb技術・データサイエンス・機械学習のプロダクト化および顧客への導入支援・コンサルティングに携わってきました。現在は独立し、アフリカ・アジア・北米の企業や個人を対象に、テクノロジー戦略の策定・実装をお手伝いしています。アフリカのマラウイでは現地企業のICTディレクターとして、デジタル・トランスフォーメーションを推進。詳しい経歴はCV を参照ください。ご意見・ご感想およびお仕事のご相談は [email protected] まで。
近況免責事項
- Amazonのアソシエイトとして、当サイトは amazon.co.jp 上の適格販売により収入を得ています。
- 当サイトおよび関連するメディア上での発言はすべて私個人の見解であり、所属する(あるいは過去に所属した)組織のいかなる見解を代表するものでもありません。
- 当サイトのコンテンツ・情報につきまして、可能な限り正確な情報を掲載するよう努めておりますが、個人ブログという性質上、誤情報や客観性を欠いた意見が入り込んでいることもございます。いかなる場合でも、当サイトおよびリンク先に掲載された内容によって生じた損害等の一切の責任を負いかねますのでご了承ください。
- その他、記事の内容や掲載画像などに問題がございましたら、直接メールでご連絡ください。確認の後、対応させていただきます。