8月1日から9月30日まで、大学院の同期で小学生時代は落ち着きがなかった @ganmacs と、小学校の給食ではソフト麺が出なかった @amaya382 と一緒に Treasure Data (TD) Summer Internship に参加した。
インターンの途中で1週間アメリカへ行ってしまうという事情を酌んだ上で採用していただき、限られた期間で物凄く適切な課題設定とメンタリングを行なってくださった@myuiさんには頭が上がらない。本当にありがとうございました。
TDインターン全体としての見どころは、
- 全方位ウルトラエンジニアで気を抜くと死ぬ環境
- 丸の内の一食1000円オーバーの飲食店事情
- ラウンジの炭酸強めでおいしい炭酸水
にあったと思う。うん。
※いろいろ書きますが、内容は全て僕個人の考えで、TDや@myuiさんの意見を代表するものではありません。念のため。
Treasure Data Summer Internship 2016
6月ごろから募集が行われていて、選考やインターン中の雰囲気は基本的に以下の記事に書かれている通りだった。
僕のインターンを通してのテーマは Real-world Machine Learning だったように思う。具体的にやったことを列挙すると以下のような感じで、1つの機能をじっくり腰を据えて実装する、というよりは様々な側面から現場での機械学習に触れるような内容だった。
- Hivemallへのユーザ定義関数 (UDF) 実装
- TD社内のDatadogメトリクスからの異常検知
- チュートリアル記事「Random Forestを用いたTreasure Data (Hivemall) 上でのサービス解約予測」の執筆
- 機械学習絡みのセールス/コンサル目的のミーティングへの同席
HivemallへのUDF実装
HiveのUDFを実装するのは最初"お作法"的なものがよくわからず戸惑ったけど、既存の実装やプログラミングHiveを参考にしつつ何とか進めた。少しだけお近づきになれた気がする。
ランキング問題用の評価関数というのは地味だけど、僕の興味と密接に関係していて、応用上重要な役割を果たす関数でもあるのでウキウキしながら実装した。(推薦とは多くの場合において本質的にはランキング問題となる。)理解不足だったり、そもそも間違えて解釈していたところが明らかになったのも良かった。(参考:Metric Learning to Rank)
異常検知に関しては、線形計算が好物なので Singular Spectrum Transformation を論文読みながら実装してるときが一番ノリノリだった。ChangeFinder はハイパーパラメータの闇が深いので厳しい。
![]() ▲ キメラ感の無いクールなHivemallロゴ
▲ キメラ感の無いクールなHivemallロゴ
Hivemallが実現したクエリで記述するプログラミング不要の機械学習というパラダイムを@myuiさんは ポストMahout と位置づけている。しかし現実には「プログラミングのほうが楽だ」という意見もあるだろうし、最適解はデータの規模や解析基盤の構成、データサイエンティストの技量に応じて異なって然るべきだ。
インターン参加中にHivemallのApache Incubatorプロジェクト入りが決定し、今後より多くの機能がサポートされていくことと思うが、機械学習戦国時代に生きる僕たちは常に ポストHivemall の可能性も見据える必要があるのだと思う。
実際にHivemallを触りながら、漠然とそんなことを考えていた。
TD社内のDatadogメトリクスからの異常検知
Datadogは公式でメトリックに対する外れ値スコア計算をサポートしていて、メトリックごとのスコアに閾値を設けてアラートを設定すれば、異常検知っぽいことができる。しかしDatadogのアラートは AND や OR のような演算を組み合わせた複雑な条件設定には対応していないので、大量のメトリクスを画面いっぱいに表示して監視するようなシーンで、複数メトリクスの状態から総合的に判断される異常みたいなものが定義できない。
というわけでDatadogの外側にその機構を作ってみましょう、という話になり、インターンを通して以下のようなシステムをEC2上に作って評価・改善を行なった。
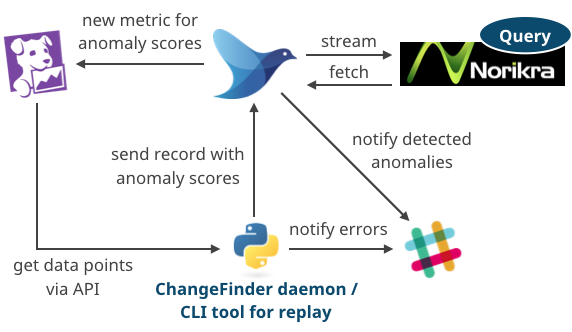
- DatadogからAPI経由で指定メトリクスの値を取ってきて、
- 複雑な入力にも対応できる異常検知フレームワーク ChangeFinder を実装したPythonデーモンが異常スコアを計算して、
- スコアをくっつけたレコードをFluentに投げて、
- Fluentは
- 異常スコアのモニタリング用にそれをDatadogにPOSTしつつ
- 複数メトリクスに対する複雑な条件によるフィルタリング(検知)のためにComplex Event Processing (CEP) エンジンNorikraにも渡して、
- Norikra側で引っかかった異常はFluent経由でSlackに通知される。
TDインターンは全てガチなので、当然これも「インターンの課題として作って終わり」的なモノではなくて、日常的なメトリクス監視業務の一部として実際に使うことを想定して作った。けれど、話はそんなに簡単ではなかった。
まずDatadog APIに依存している時点でメトリクス収集の頻度には制限があるし、ChangeFinder は先述の通りハイパーパラメータの闇が深すぎて正直使いづらすぎる。そしてNorikra、これは良し悪し以前の議論の余地が多分に残されている。
https://twitter.com/takuti/status/762199014863278080
https://twitter.com/frsyuki/status/781722538887958528
https://twitter.com/tagomoris/status/781722722233561088
というわけで、経験値として得たものは多かったけど、やり残したことや反省点も多くあるので、これに関してはもう少し使いやすい形まで仕上げて後日改めてブログ記事にでもしたい。
重要なのは、手法がどれほど理論的に素晴らしいものであっても、実際にはそれ以外の部分に様々な困難が存在するということ。そしてそれらに立ち向かうことがいかに難しいことであるか。
チュートリアル記事の執筆
TDは「エンジニアがすごい会社」というイメージが強すぎて実際どんなビジネスをしているのか正直謎だったけど、Data Management Platform (DMP) を提供する会社ですよ、みなさん。ゆえに、お客様はデータに関する様々な課題を抱えていて、それに対してDMPの活用方法・事例を示すことが我々の重要な役割のひとつ。
今回はその一例として、pandas-td も利用しつつTD上でのサービス解約予測を行なった。データはこれで、3333サンプルしかないのでscikit-learnとか使ったほうが全然楽なのだけど、そこはご愛嬌。
機械学習・データサイエンスの文脈で第三者に手法の"良さ"を正しく伝えるためには、まず僕らが数式の気持ちになってあげることが大切だと思う。記事やスライドに数式をそのまま書いたら負け、でもモデルの裏側にある概念は正しく伝える…まぁこれが大変なのだけれども…。
セールス/コンサル目的のミーティングへの同席
こればかりは残念ながら詳細を書くことができないが、TDはセールスの会社(CTO談)であり、その一端を感じることのできる素晴らしい機会だった。
「技術はユーザの存在があってこそ」という気持ちがずっとあって、これは機械学習も例外ではない。どのアルゴリズムを使うか?目的変数はなにか?ハイパーパラメータはどうするか?特徴ベクトルは?といったことは全てデータや目的、システム上の制約などに依存する。そしてユーザありきの機械学習では大抵の場合、目的を達成するためにヒューリスティクスが多分に投入される。そのあたり、バランスがとても重要なのだ。数学的に面白い方向性や、少し特殊な問題設定の大喜利的な提案、計算リソースにモノを言わせる手法はたくさんあるけれど、その点なんか違うよね〜と感じてしまう。むつかしい。
そういった世界で"ちょうどいい"解決策を個々のユーザに示すためには、やっぱりコミュニケーションとか、経験に基づく勘とかが大事で、ミーティングへの同席はそれを再認識する良いきっかけになった。
まとめ
良くも悪くも、現実の機械学習は多様なスキルの組み合わせの上に成り立っている。TDインターンを通してその楽しさと難しさを痛感した。
2ヶ月はあっという間だったけれど、楽しくて優秀な同期2人と、とても尊敬できるメンター、そして凄い(それ以外のうまい表現が見つからない)社員のみなさんのおかげで、濃密な時間を過ごすことができた。本当にありがとうございました。
M2の夏休みをフルタイムインターンに捧げるというのは一見リスキーだけど、まぁ毎週ジムにいったり、途中で国際会議ショートペーパー1本書いて投稿するくらいの余裕はあったので、来年も募集があったらみなさん積極的に応募するとよいです。特に機械学習系のみなさん、研究所やデータサイエンティスト的なポジションのインターンも良いけれど、TDもかなり良いですよ。論文のIntroductionの説得力が増すと思います。
最後に僕の最終発表のスライドを貼っておきます。何か変なことを言っていたり、俺ならこうする!みたいな話があったらぜひお聞かせください。
サポートする
一杯のコーヒーを贈るカテゴリ
あわせて読みたい
- 2017年9月10日
- Yahoo!の異常検知フレームワーク"EGADS"
- 2017年5月7日
- Hivemall on Dockerを試すぜ
- 2017年3月31日
- 修士課程で機械学習が専門ではない指導教員の下で機械学習を学ぶために
書いた人: Takuya Kitazawa(たくち)
長野県出身、カナダの首都・オタワを拠点に活動する技術者です。10年以上にわたりB2B/B2Cの各領域でWeb技術・データサイエンス・機械学習のプロダクト化および顧客への導入支援・コンサルティングに携わってきました。現在は独立し、アフリカ・アジア・北米の企業や個人を対象に、テクノロジー戦略の策定・実装をお手伝いしています。アフリカのマラウイでは現地企業のICTディレクターとして、デジタル・トランスフォーメーションを推進。詳しい経歴はCV を参照ください。ご意見・ご感想およびお仕事のご相談は [email protected] まで。
近況免責事項
- Amazonのアソシエイトとして、当サイトは amazon.co.jp 上の適格販売により収入を得ています。
- 当サイトおよび関連するメディア上での発言はすべて私個人の見解であり、所属する(あるいは過去に所属した)組織のいかなる見解を代表するものでもありません。
- 当サイトのコンテンツ・情報につきまして、可能な限り正確な情報を掲載するよう努めておりますが、個人ブログという性質上、誤情報や客観性を欠いた意見が入り込んでいることもございます。いかなる場合でも、当サイトおよびリンク先に掲載された内容によって生じた損害等の一切の責任を負いかねますのでご了承ください。
- その他、記事の内容や掲載画像などに問題がございましたら、直接メールでご連絡ください。確認の後、対応させていただきます。