Holt-Winters Method(別名: Triple Exponential Smoothing)というデータの予測手法がある。これについて素晴らしい解説記事があるので読みながら実装していた。
コードは takuti/anompy にある。
この手法、Graphite が実装しているということもあり、近年ではDevOpsコミュニティを中心に一躍有名になったんだとか。
ここでは解説記事の内容に沿って、Holt-Winters Method に至るまでに知っておくべき手法たちの“気持ち”をまとめる。数式は元記事やWikipediaに譲る。
問題
『連続するN点の時系列データを観測していたとき、N+1点目の値を予測する問題』を考える。
もし次の瞬間の値が予測できれば、そこからデータの“異常”を察知することができる。
たとえばDatadogなどで監視しているシステムのメトリクスを対象とすれば、予測結果からいち早くアラートを発することができる。
以後、サンプルとして次のデータ列に対して観測→予測を繰り返すことを考えよう:
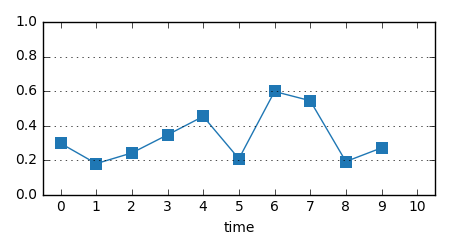
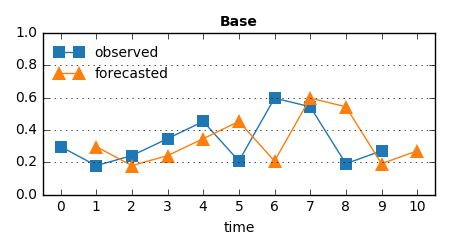
手法1: 直近の観測値をそのまま予測値として返す
考えられる最も単純な手法のひとつ。見たものをそのまま返しているので、オウム返し的未来予測。これを BaseDetector と呼ぼう。
class BaseDetector(object):
def __init__(self, observed_0, threshold=0.):
self.threshold = threshold
self.observed_last = observed_0
def detect(self, observed_series):
"""Launch forecasting for each observed data point based on a model.
Return labeled forecasted series if each observed data point is anomaly or not.
Args:
observed_series (list of float): Observed series.
Returns:
list of (float, boolean): Forecasted series with anomaly label.
"""
forecasted_series = []
for observed in observed_series:
forecasted_series.append((self.observed_last, self.observed_last > self.threshold))
self.observed_last = observed
return forecasted_series
時系列データの最初の1点 observed_0 と、予測値に対する閾値 threshold を設定さえ渡せばよい。あとは新しいデータを読むたびに直近の値を更新・保持し続ける。
当然、予測値のグラフは観測値を1時刻だけシフトさせたものになる:
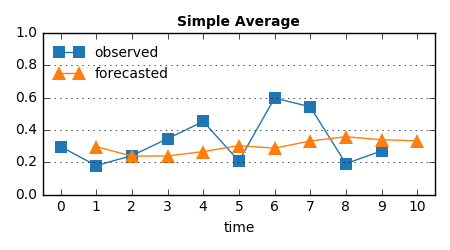
手法2: これまでの平均を予測値として返す
手法1はさすがに頭が悪すぎるので、もう少し工夫して、“データ列全体の傾向”を平均値という形でつかめるようにした。
しかし異常と判断したい値の急激な変化も、大域的にみるとほぼ無意味。ゆえに、大きく予測を外すことはないが、有意義な予測もしてくれない、そんな難しい子:
手法3: 直近N点の平均を予測値として返す
ある窓幅を決めて、“データ列全体の傾向”(手法2)ではなく“最近の傾向”、すなわちトレンドを平均値という形でつかむ。
直近3点を使った場合:
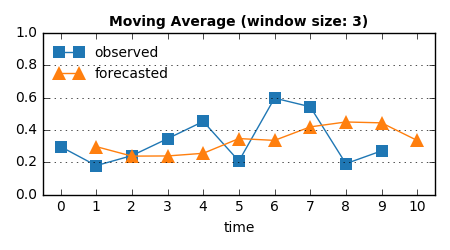
時刻6, 7の値の一時的な増加傾向を捉えて、時刻7, 8, 9あたりは高い予測値となっていることがわかる。
手法4: 直近N点の重み付き平均を予測値として返す
直近N点の中でも、現在時刻の値に大きく寄与する点とそうでない点があるかもしれない。そんな事情も踏まえた、より柔軟な移動平均の計算。
手法3と同様に、直近3点の平均を予測値とする。でも今度は、その3点に [0.1, 0.1, 0.8] という重みを付けて、直前の1点を特に重視してみる。そして、[0.333, 0.333, 0.333] という一様な重みと比較すると:
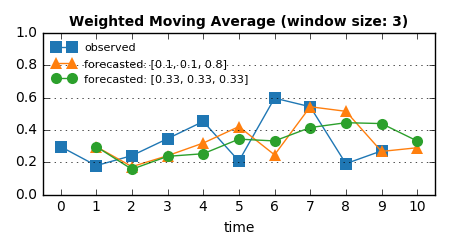
weights = [0.1, 0.1, 0.8] のグラフは手法1(直近の観測値をそのまま使う)に近いものになっている。一方、一様な重み weights = [0.333, 0.333, 0.333] なら、それは手法3の結果(重み無し移動平均)にほぼ等しい。
重みは何らかの仮説に基づいて決めればよい。万能な予測器など世の中に存在しないので、こういったヒューリスティクスを取り入れる余地のある直感的なアルゴリズムの設計は素晴らしい。平均値を求めているだけだからといって侮ってはいけない。
手法2から4を1つの AverageDetector としてまとめると、窓を deque で表現してこんな感じ:
from collections import deque
class AverageDetector(BaseDetector):
def __init__(self, observed_0, window_size=None, weights=None, threshold=0.):
self.moving_average = window_size is not None
self.weighted = weights is not None
if self.moving_average:
self.window = deque([observed_0], maxlen=window_size)
if self.weighted:
assert window_size == len(weights)
self.weights = weights
else:
self.num_observed = 1
self.threshold = threshold
self.average = observed_0
def detect(self, observed_series):
forecasted_series = []
for observed in observed_series:
forecasted_series.append((self.average, self.average > self.threshold))
if self.moving_average: # moving average
self.window.appendleft(observed)
if self.weighted:
self.average = sum([vi * wi for vi, wi in zip(self.window, self.weights)])
else:
self.average = sum(self.window) / len(self.window)
else: # simple average
# m_{n} = ((n - 1) m_{n-1} + x_n) / n
# `(n - 1) m_{n-1}` returns sum of x_1, x_2, ..., x_{n-1}
self.num_observed += 1
self.average = self.average + (observed - self.average) / self.num_observed
return forecasted_series
window_size が与えられているか、 weights が与えられているか、に応じて手法2, 3, 4を切り替える。
これも BaseDetector と同様で、最初の1点 observed_0 と 閾値 threshold を与えれば、予測値を元に異常が検知できる。
手法5: 直近の観測値(今)と予測値(これまでの積み重ね)の重み付き和で次の値を予測する
手法4はヒューリスティクスを窓幅と各点の重みという形で取り入れていて、これはなかなか筋がよかった。でも、実際にはそこまで厳密な仮説は立てられないことが多い。
そこで、もう少し単純に『今』と『これまで』のバランスを取りながら予測する手法を考える。これが Exponential Smoothing。
この手法では alpha という0から1の間の値をとるパラメータを導入する。そして、この値1つで予測値がどれだけ直近の観測値を重視するかをコントロールする。
手法4の重み付き移動平均では [0.1, 0.1, 0.8] という重みで『直近の観測を特に重視する』という状態を表現した。Exponential Smoothing では、これは alpha に大きな値を設定することに等しい。
alpha = 0.9 の結果は手法1(直近の値をそのまま使う)に近くなり、一方 alpha = 0.1 とすれば、それは手法2(これまでの全観測値の平均を使う)と似た平坦な出力となる:
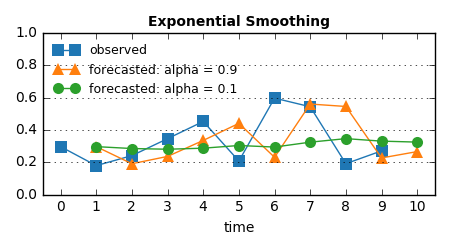
なおこの手法、数式上では『次の予測値』を求めるために『1つ前の予測値』を使っており、予測値に関して再帰的な式になっている。これが "Exponential" と呼ばれる理由:
forecasted = alpha * observed + (1. - alpha) * forecasted
手法6: 予測値の変動の大きさから、データのトレンド(増加・減少傾向)をとらえる
Exponential Smoothing では『今』の観測点1つと『これまで』のバランスで予測値を求めていた。これは、手法4の重み付き移動平均から窓幅の概念が消え去った、単純化された手法ともいえる。
一方で、より柔軟に、『これまで』がどれだけ最近(過去)を指すのか設定したい―つまりデータの“最近の傾向”をよしなにとらえたい、という要望もある。
そこで、手法5で『観測値(今)と予測値(これまで)の重み付き和』で求めていた値を新たにレベルと呼び、:
level_last = level
level = alpha * observed + (1. - alpha) * forecasted
『一度の観測でレベルがどれだけ変動したか』、つまり level - level_last を(最新の)トレンドとみなすことにする。
そして、『次のトレンド』を『最新のトレンド』と『これまでのトレンド』の重み付き和で計算する:
trend = beta * (level - level_last) + (1. - beta) * trend
(重み beta は0から1の間の値をとる)
最終的に、レベルとトレンドの和を予測値とする。これが Double Exponential Smoothing:
forecasted = level + trend
最新のトレンド(増加・減少傾向)に敏感であってほしいなら beta を大きな値に設定すればよい。
alpha = 0.5 に固定して beta = 0.9 の場合と beta = 0.1 の場合を比較すると、beta が大きいときのほうが実測値の増加・減少に敏感に反応した予測値を返すことがわかる:
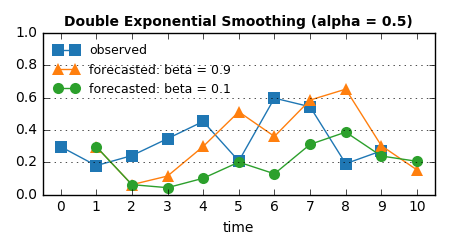
forecasted = level + trend を展開すると右辺に forecasted が2つ登場するので "Double Exponential" です。
手法7: データの季節性を考慮する
現実世界の時系列データには、往々にしてある種の季節性 (seasonality) がみられる。
たとえばバッチジョブは深夜〜早朝にかけてスケジューリングされることが多いので、システムのあるメトリクスは『毎日』『その時間帯』に似たような増加傾向を示すだろう。
そのような時系列データに対して、Double Exponential Smoothing の予測値に季節性を加味した Triple Exponential Smoothing という手法を考える。これこそが Holt-Winters Method と呼ばれている手法の正体。
Holt-Winters Method は季節性があると思われる時系列データ initial_series と季節の周期 season_length を入力とし、予め『周期上のこのタイミングなら予測値はこれくらい』という見積もりを1周期分たてておく:
def init_holt_winters(initial_series, season_length):
# ...
return seasonals # [s_1, s_2, ..., s_{season_length}]
この周期上の予測値 seasonals は、適当な初期値と initial_series に基づいて計算される。具体的には、initial_series[i] は、seasonals[i % season_length] の更新に使われる。
まず、Double Exponential Smoothing と同様にレベルとトレンドを求める:
level_last = level
level = alpha * (initial_series[i] - seasonals[i % season_length]) + (1. - alpha) * (level + trend)
trend = beta * (level - level_last) + (1. - beta) * trend
ただし、ここでいう“観測値”は『観測値(今)と、対応する周期上での点の見積もり(これまで)の差 initial_series[i] - seasonals[i % season_length]』である。
そして、周期上の予測値が次のように更新される:
seasonals[i % season_length] = gamma * (initial_series[i] - level) + (1. - gamma) * seasonals[i % season_length]
ここでも重み付き和が登場し、新たにパラメータ gamma が導入された。このパラメータは0から1の間で『seasonals[i % season_length] の値の更新で、どれだけ initial_series[i] を考慮するか』の重みとなる。
なお、Holt-Winters Method が "Triple Exponential" であるワケは、seasonals[i % season_length] = ... を展開すれば右辺に seasonals[] が3回登場するから。
さて、initial_series をすべて処理して最終的な level と trend の値、および見積もり seasonals が得られたら、あとは未来予測をするだけだ。第n点目の予測値は次で得られる:
forecasted = level + n * trend + seasonals[(n - 1) % season_length]
試しに、これまで使ってきたダミーの時系列データを周期3の季節性データとして読み込み、その先の予測値を出してみよう:
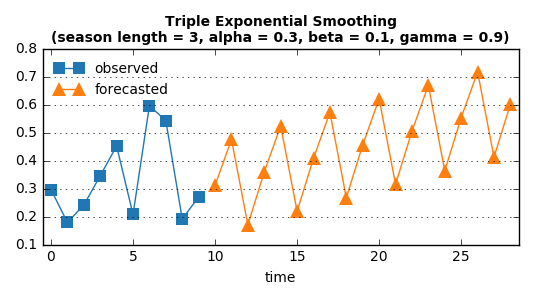
3時刻周期で予測値が得られている。
予め計算された trend について、第n点目の予測では n * trend を周期上の点の見積もり値に加算するので、グラフは右上がり(または右下がり)となる。この上がり/下がり具合はパラメータ alpha や beta によってコントロールできるが、最適値を見つけるのはむずかしい。というか、そもそもどんな結果を“最適”とするのか、という問題がある。
まとめ
オウム返し的未来予測から出発して Holt-Winters Method まで、シンプルな予測手法の気持ちを感じた。
この記事の主役は Holt-Winters Method だけど、季節性が顕著に現れない時系列データも世の中にはたくさん存在するし、(いずれも0-1の範囲とはいえ)3つのパラメータ alpha, beta, gamma の最適な値の組み合わせを発見するのは容易ではない。というわけで、個人的には Double Exponential Smoothing 推しです。はい。
異常検知と聞いてステキな数式とゴツいアルゴリズムを持ち出したくなる気持ちも分かるけれど、「このユースケースでそれって本当に必要ですか?」という議論が大切だと思います。案外ここに書いてあることだけで十分かもね。
サポートする
一杯のコーヒーを贈るカテゴリ
あわせて読みたい
- 2020年10月18日
- マーケティング最適化のためのアトリビューション:単一タッチポイント全振りパターンからShapley Valueモデルまで
- 2017年9月10日
- Yahoo!の異常検知フレームワーク"EGADS"
- 2015年12月8日
- ストリームデータ解析の世界
書いた人: Takuya Kitazawa(たくち)
長野県出身、カナダの首都・オタワを拠点に活動する技術者です。10年以上にわたりB2B/B2Cの各領域でWeb技術・データサイエンス・機械学習のプロダクト化および顧客への導入支援・コンサルティングに携わってきました。現在は独立し、アフリカ・アジア・北米の企業や個人を対象に、テクノロジー戦略の策定・実装をお手伝いしています。アフリカのマラウイでは現地企業のICTディレクターとして、デジタル・トランスフォーメーションを推進。詳しい経歴はCV を参照ください。ご意見・ご感想およびお仕事のご相談は [email protected] まで。
近況免責事項
- Amazonのアソシエイトとして、当サイトは amazon.co.jp 上の適格販売により収入を得ています。
- 当サイトおよび関連するメディア上での発言はすべて私個人の見解であり、所属する(あるいは過去に所属した)組織のいかなる見解を代表するものでもありません。
- 当サイトのコンテンツ・情報につきまして、可能な限り正確な情報を掲載するよう努めておりますが、個人ブログという性質上、誤情報や客観性を欠いた意見が入り込んでいることもございます。いかなる場合でも、当サイトおよびリンク先に掲載された内容によって生じた損害等の一切の責任を負いかねますのでご了承ください。
- その他、記事の内容や掲載画像などに問題がございましたら、直接メールでご連絡ください。確認の後、対応させていただきます。