追記 (2017/03/10)
現在の内容は過度な簡略化と不完全な説明を含むので、それを踏まえて読んでいただけると幸いです。(後日更新予定)
https://twitter.com/myui/status/840089982991708160
二値分類器の評価指標として Area Under the ROC Curve (AUC) がある。これは Root Mean Squared Error (RMSE) が測る『誤差』や Precision, Recall で求める『正解率』のような直感的な指標ではないので、どうもイメージしづらい。
というわけで実際に実装して「結局AUCって何?」を知る。詳しくは以下の論文を参照のこと。
- Tom Fawcett. An introduction to ROC analysis. Pattern Recognition Letters 27 (2006) 861–874.
AUCとは結局なにを計算しているのか
サンプルに対して 0から1の範囲でスコア(確率)を与える二値分類器 の精度を評価することを考える。
このときAUCは『予測スコアでサンプルを(降順)ソートしたときに、True Positive となるサンプルが False Positive となるサンプルより上位にきているか』ということを測る。つまり、ラベル 1 のサンプルに正しく高スコアを与える予測器であるか を見ている。
推薦などのランキング問題の評価でもAUCが登場するけど、イメージはそれとほぼ同じ。
たとえば、以下のようなソート済スコアと真のラベルのペアがあったとき、真のラベルが 1,1,1,0,0 と並ぶことが理想。しかし今は 1,1,0,1,0 となっているので、このスコアリングは最高精度とは言えない。
| 予測スコア | 真のラベル |
|---|---|
| 0.8 | 1 |
| 0.7 | 1 |
| 0.5 | 0 |
| 0.3 | 1 |
| 0.2 | 0 |
AUCの実装 is 台形(長方形)の面積の逐次計算
この True Positive が False Positive より上位にランキングされるか という考えを念頭に置くとAUCの実装が理解しやすい。
具体的には、降順にソートされた予測スコア pred と、それらの真のラベル label を順に処理して、各時点での True Positive, False Positive の増分から面積を求めて加算的に計算していく。
コードにすると以下のような雰囲気。
def trapezoid(x1, x2, y1, y2):
"""与えられた長方形(台形)の面積を求める
"""
base = abs(x1 - x2)
height = (y1 + y2) / 2.
return base * height
def auc(pred, label):
"""ソート済スコアとラベルのリストからAUCを求める
"""
n = len(pred)
a = 0.
score_prev = float('-inf')
fp = tp = 0
fp_prev = tp_prev = 0
# ソート済スコアとラベルのペアを逐次的にみていく
for i in range(n):
if pred[i] != score_prev:
# True Positive (False Positive) の増分がつくる長方形の面積を加算
a += trapezoid(fp, fp_prev, tp, tp_prev)
score_prev = pred[i]
fp_prev = fp
tp_prev = tp
# 現時点での True Positive, False Positive 数
if label[i] == 1:
tp += 1
else:
fp += 1
a += trapezoid(fp, fp_prev, tp, tp_prev)
# 最大面積で正規化
return a / (tp * fp)
やっていることを図で描くと以下のような感じ。False Positive-True Positive のグラフ上に作られる長方形の面積を足し合わせていく。
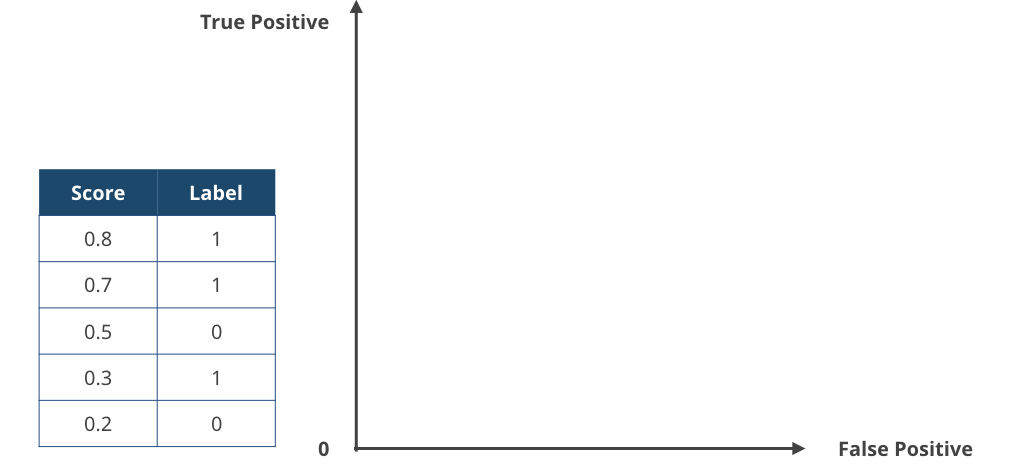
▲ 初期状態。そもそも ROC Curve は横軸に False Positive Rate、縦軸に True Positive Rate をとったグラフなので、AUCの計算でも False Positive, True Positive の数をそれぞれの軸にとる。
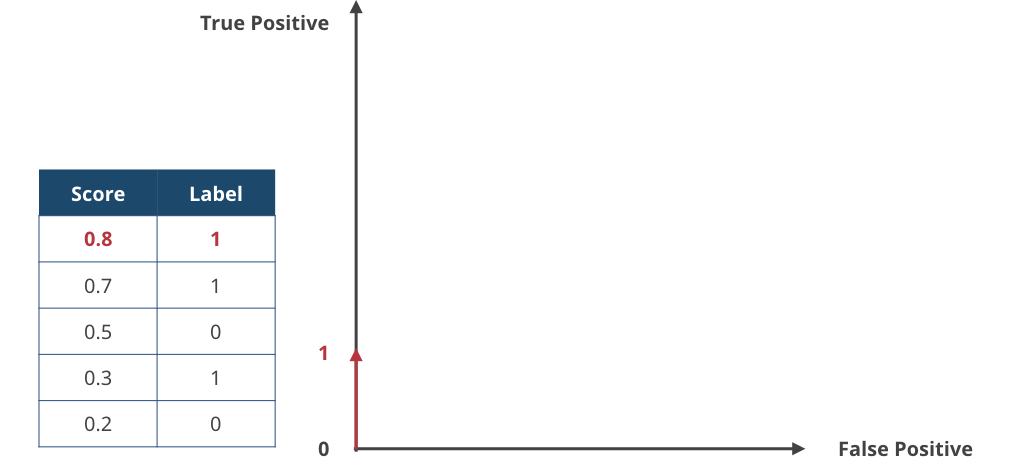
▲ 1サンプル目、最もスコアが高かったサンプル。label = 1 だったので、True Positiveカウントを増やす。
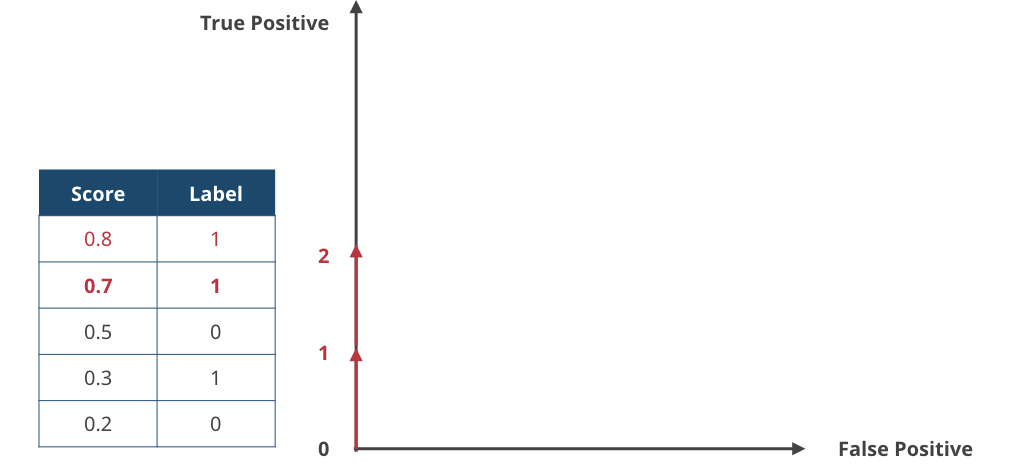
▲ 2サンプル目。同じく label = 1 だったので、True Positiveカウントを増やす。

▲ 3サンプル目。label = 0 なので False Positive カウントを増やす。
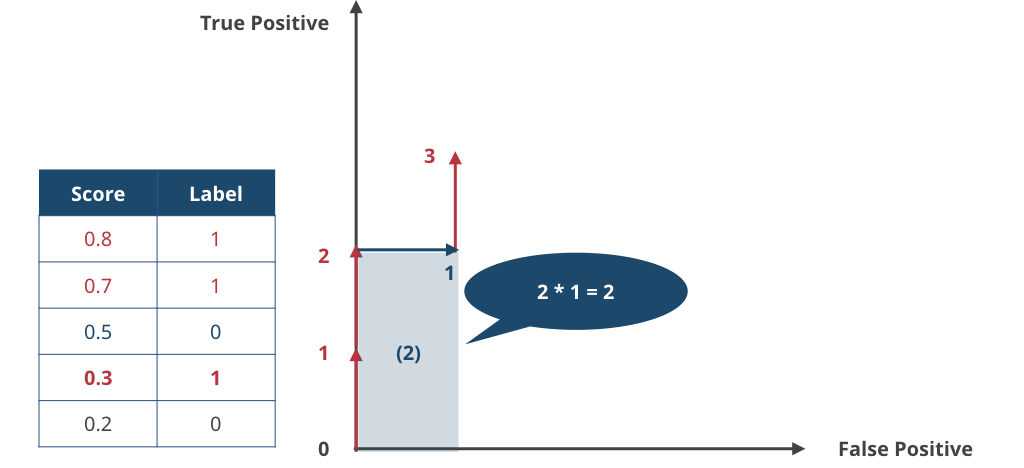
▲ 4サンプル目。label = 1 なので True Positive + 1。ここまでくると、グラフの下に長方形をみることができる。この面積は横2×縦1=2である。
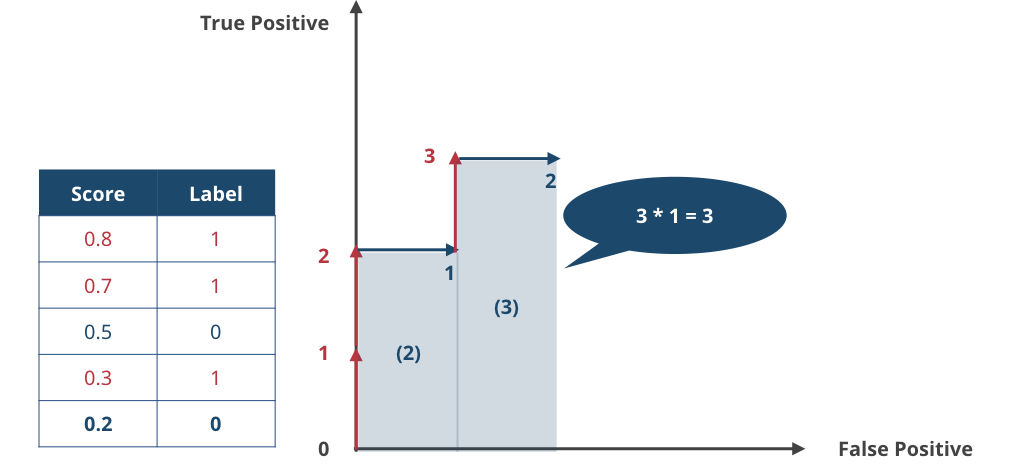
▲ 5サンプル目は False Positive。これで最後なので、4サンプル目以降にできた大きな長方形の面積を求めると縦3×横1=3となる。つまり、ソート済みサンプルから得られた False Positive-True Positive グラフの下の面積は 2+3=5 だとわかる。
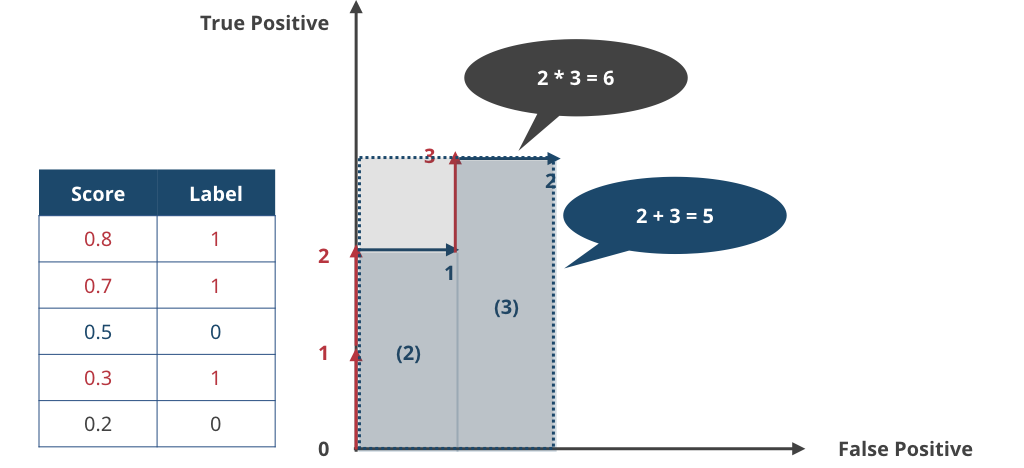
▲ ROC Curve は True Positive (False Positive) "Rate" を考えるので、最後に得られた面積を正規化する。今回は全部で label = 1 のサンプルが3つ、label = 0 のサンプルが2つあったので、最大で 縦3 × 横2 = 面積6 の長方形が得られるはず。というわけで、この場合のAUCは 5 / 6 = 0.83333 となる。
以上、これがAUCによる精度評価の内側。例えばラベルが 1,1,1,0,0 の順で来ればAUCは最高の 1.0 になって、逆に 0,0,1,1,1 の順で来れば最悪の 0.0 になる。
まとめ
AUCによる精度評価の “気持ち” を実装しながらつかんだ。True Positive が False Positive より上位にランキングされるか という視点と、それを False Positive-True Positive グラフの下の面積 に対応付けることがポイント。
ROC Analysis はそれだけでワークショップが開催できるくらい難しいトピックだけど、実用上はこれくらい分かっていれば十分な気がする。
サポートする
一杯のコーヒーを贈るカテゴリ
あわせて読みたい
- 2021年11月17日
- もしも推薦システムの精度と多様性が単一の指標で測れたら
- 2017年11月4日
- Over-/Under-samplingをして学習した2クラス分類器の予測確率を調整する式
- 2017年3月10日
- Area Under the ROC Curve (AUC) を並列で計算するときに気をつけること
書いた人: Takuya Kitazawa(たくち)
長野県出身、カナダの首都・オタワを拠点に活動する技術者です。10年以上にわたりB2B/B2Cの各領域でWeb技術・データサイエンス・機械学習のプロダクト化および顧客への導入支援・コンサルティングに携わってきました。現在は独立し、アフリカ・アジア・北米の企業や個人を対象に、テクノロジー戦略の策定・実装をお手伝いしています。アフリカのマラウイでは現地企業のICTディレクターとして、デジタル・トランスフォーメーションを推進。詳しい経歴はCV を参照ください。ご意見・ご感想およびお仕事のご相談は [email protected] まで。
近況免責事項
- Amazonのアソシエイトとして、当サイトは amazon.co.jp 上の適格販売により収入を得ています。
- 当サイトおよび関連するメディア上での発言はすべて私個人の見解であり、所属する(あるいは過去に所属した)組織のいかなる見解を代表するものでもありません。
- 当サイトのコンテンツ・情報につきまして、可能な限り正確な情報を掲載するよう努めておりますが、個人ブログという性質上、誤情報や客観性を欠いた意見が入り込んでいることもございます。いかなる場合でも、当サイトおよびリンク先に掲載された内容によって生じた損害等の一切の責任を負いかねますのでご了承ください。
- その他、記事の内容や掲載画像などに問題がございましたら、直接メールでご連絡ください。確認の後、対応させていただきます。