Nowadays, there is almost no question that data is the new oil. But, do we really have a clear picture of where the oil is coming from, in which route, by whom, how, and when?
In practice, the massive continuous flows of the oil have forced us to radically automate and abstract the complex data pipelines. Eventually, we become able to "forget" about the data sources and intermediates both in a positive and negative way. Here, I strongly believe we (as a modern data-driven developer) must be more conscious about individual data points we are interacting with, and I see data lineage as a means of ethical product development in this regard.
To give an example, if you own a complex data pipeline on Apache Airflow, the tool will nicely automate your day-to-day ETL processes and hides deep contexts about the data.
On one hand, the effort unlocks developers to focus purely on an essential problem, which is commonly tied to an ultimate destination of the data flow. That is, abstraction and automation improve developer's productivity.
On the negative side, however, such a modern data-driven system deteriorates developer's consciousness, awareness, and understanding about the detail of data.
When we see a dataset on a Jupyter notebook, we shouldn't forget the fact that there is a real world upstream. The oil is not a toy for unconscious software engineers and/or data scientists, and it's not a tool for capitalistic competition based on an extrinsic motivation. It is rather highly sensitive and precious information depicting everyone's beautiful life. Thus, I personally want to be a person who doesn't overlook a hidden aspect of data in front of me; I should literally appreciate individual rows on a pandas DataFrame.
As I mentioned at the top, this is where data lineage can help. Commonly speaking, by tracking a source, destination, and metadata of every single step in the pipelines, data lineage helps developers to effectively reduce a chance of errors, easily debug an issue, and accurately audit what's going on behind the scene.
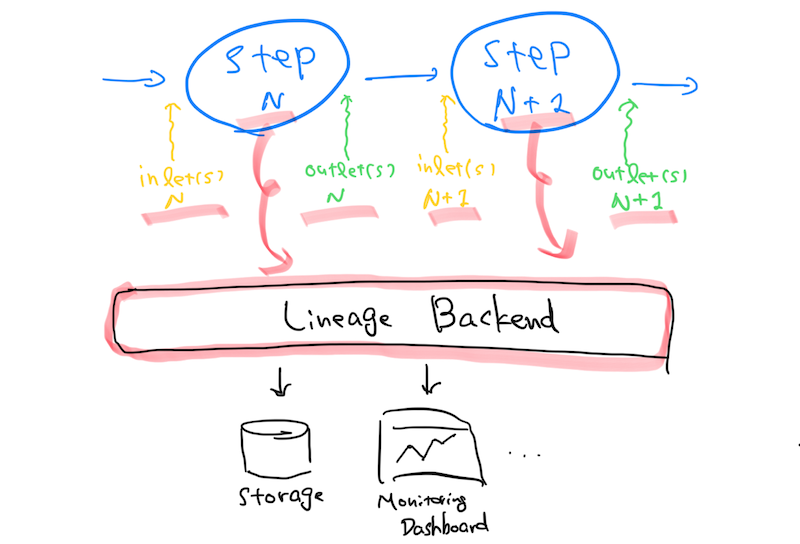
Every steps in a pipeline emit "What's incoming (outgoing) from (to) where"-type of information to a certain lineage backend, and the system eventually sends the information to dedicated service(s) where we can train our consciousness about the data.
In the case of Apache Airflow, there is an experimental feature we could use. Assume a BashOperator task takes one file (1 inlet) and generates three resulting files (3 outlets) as follows:
f_in = File(url="/tmp/whole_directory/")
outlets = []
for file in FILE_CATEGORIES:
f_out = File(url="/tmp/{}/{{{{ data_interval_start }}}}".format(file))
outlets.append(f_out)
run_this = BashOperator(
task_id="run_me_first", bash_command="echo 1", dag=dag, inlets=f_in, outlets=outlets
)
Once the task is executed, its lineage becomes accessible through XCom:
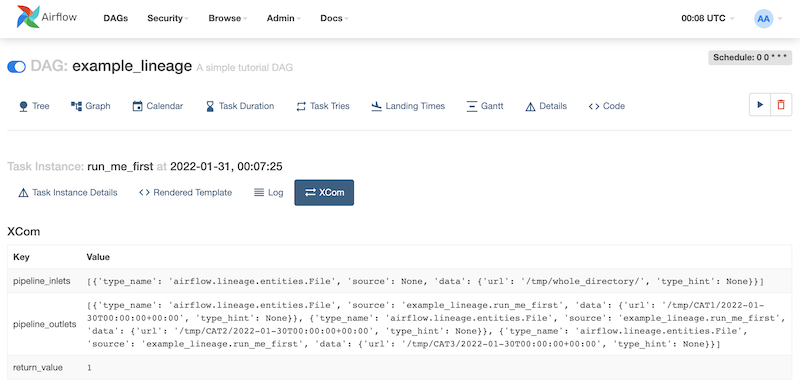
Meanwhile, a configured lineage backend separately processes the information:
from airflow.lineage.backend import LineageBackend
import requests
class ExampleBackend(LineageBackend):
def send_lineage(self, operator, inlets=None, outlets=None, context=None):
url = "https://webhook.site/8fe779dc-10ae-4917-8f41-685723a31064"
data = {
"operator": operator.__class__.__name__,
"inlets": [str(inlet) for inlet in inlets],
"outlets": [str(outlet) for outlet in outlets],
"context": str(context),
}
requests.post(url, json=data)
operator.log.info(f"Sent lineage to {url}: {data}")
* See takuti-sandbox/airflow-test for the complete example.
Although it's a simple example that a webhook receives the plain data, a downstream service can be anything e.g., RDB, monitoring tool, notification, and Slack channel.
The point here is how easily we can take our first step toward conscious data engineering. Implementing a mechanism that forces us to be aware of not only final outputs but original sources and intermediates would be critical to grow data ethics in the large.
This article is part of the series: Productizing Data with PeopleSupport
Gift a cup of coffeeCategories
See also
- December 4, 2022
- Data Are Created, Collected, and Processed by People
- March 20, 2022
- It "Was" Ethical: Key Takeaways from UMich's Data Science Ethics Course
- February 20, 2022
- Validate, Validate, and Validate Data. But, in terms of what?
Author: Takuya Kitazawa
I am a product builder, mentor, and advocate for sustainable technology development with a decade of experience in AI/ML products, data systems, and digital transformation. Based in Canada and originally from Japan, I have lived and worked globally, including part-time residence in Malawi, Africa. Visit my portfolio to learn more about my work, or reach out to me at [email protected].
NowDisclaimer
- Opinions are my own and do not represent the views of organizations I am/was belonging to.
- I use Grammarly for correcting grammatical errors, but I do not rely on any other generative AI tools to create my blog content.
- I am doing my best to ensure the accuracy and fair use of the information. However, there might be some errors, outdated information, or biased subjective statements due to the nature of a personal website. Visitors understand the limitations and rely on any information at their own risk.
- If there are any issues with the content, please contact me so I can take the necessary action.