The field of recommender systems grows rapidly according to the recent development of practical intelligent systems. However, even though the field is exceptionally practical compared to the other computer-science-related topics, many researchers are actively studying recommendation techniques in their lab. Here is a question: what are the research trends in recommender systems?
I tried to understand the trends from word cloud by using abstract of papers accepted for ACM RecSys Conference, one of the biggest major conferences on recommendation systems.
Collecting abstract of accepted papers
Luckily, abstract of accepted RecSys papers are well-formatted on the web page in terms of HTML structure e.g., RecSys 2017 Accepted Contributions. So, first we collect the data in a text format by using a scraping tool, especially Scrapy in this article:
$ pip install scrapy
Using Scrapy is quite easy; what I need to do is to implement a scraping module named "Spider":
import scrapy
class RecSysSpider(scrapy.Spider):
name = 'recsys-spider'
def start_requests(self):
self.abstract_index = 0
if not hasattr(self, 'yy'):
self.yy = '17'
elif self.yy == '14':
self.abstract_index = 2
elif self.yy not in ['14', '15', '16', '17']:
raise ValueError('Invalid year: ' + self.yy)
url = 'https://recsys.acm.org/recsys{}/accepted-contributions/'.format(self.yy)
yield scrapy.Request(url, self.parse)
def parse(self, response):
for elem in response.css('ul.accordion li'):
yield {'abstract': elem.css('div p ::text').extract()[self.abstract_index].strip()}
This Spider module allows users to pass an argument yy to specify which year's RecSys abstract you want to get.
Once a user executes the module in a command-line, a list of abstract sentences is stored into a CSV file:
$ scrapy runspider recsys_spider.py -a yy=17 -o csv/recsys17.csv
Since the well-structured "accepted contributions" page only exists from RecSys 2014 to 2017, the argument yy simply has the 4 options. Note that utilizing xargs might be helpful to get all of the four years' abstract of papers:
$ echo 14 15 16 17 | xargs -n 1 -I{} scrapy runspider recsys_spider.py -a yy={} -o out/recsys{}.csv
Creating word cloud
A word cloud generator written in Python provides us a really simple way to create visually stimulating word cloud from text data:
$ pip install wordcloud
In fact, the generator can be used inside of our Python code, but, in this article, we just use its command-line tool as follows, for the sake of simplicity:
$ wordcloud_cli.py --text input.csv --imagefile output.png
Let's create word cloud images from the aggregated abstract of 4 years' RecSys papers:
$ echo 14 15 16 17 | xargs -n 1 -I{} wordcloud_cli.py --text csv/recsys{}.csv --imagefile png/recsys{}.png
| Year | Word Cloud |
|---|---|
| 2014 |  |
| 2015 |  |
| 2016 |  |
| 2017 |  |
Okay...the result is trivial... Everyone commonly uses the terminology of this field such as "recommendation," "model," "user," and "item" to write their abstract.
In order to make the word cloud images more meaningful, we can use custom stop words, a list of words that we do not want to use to create the images. To give an example, below I list some frequently used terms which has to be omitted:
user
users
item
items
recommendation
recommendations
model
models
content
based
algorithm
algorithms
recommender
system
systems
data
method
using
new
show
use
proposed
result
paper
information
propose
approach
approaches
dataset
technique
techniques
provide
different
problem
methods
method
one
two
present
work
task
results
However
feature
preference
preferences
(Complete list with more meaningless terms like preposition can be found here.)
Again, create word cloud images with --stopwords option:
$ echo 14 15 16 17 | xargs -n 1 -I{} wordcloud_cli.py --text csv/recsys{}.csv --imagefile png/recsys{}.png --stopwords stopwords.txt
| Year | Word Cloud |
|---|---|
| 2014 | 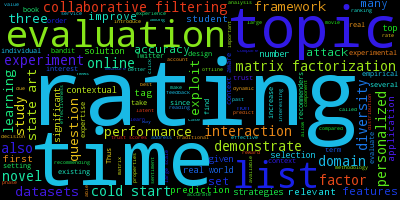 |
| 2015 |  |
| 2016 |  |
| 2017 | 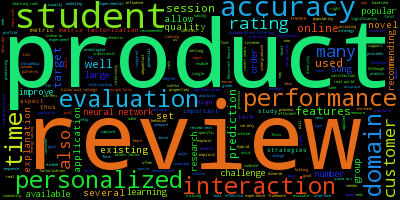 |
Yay, it looks much more interesting :)
Trends: From rating to more realistic scenario
Historically, the study on recommender systems starts from user-item rating matrix as what the GroupLens research group did on the MovieLens data. More specifically, a term "recommender systems" simply refers one well-known technique named Collaborative Filtering (or Matrix Factorization in some sense).
Here, see the word cloud from 2014 and 2015 papers; we can observe that research related to "rating" data played an important role until a couple of years ago.
In addition, we can easily find the name of classical, powerful techniques, "matrix factorization" and "collaborative filtering," in the images. (These are a little bit small and have unreadable dark colors, though.)
On the other hand, in 2016 and 2017, "rating" gets much smaller than the past two years, and it is really hard (and impossible for me) to look for "matrix factorization" and/or "collaborative filtering."
Instead of the well-known type of data and techniques, words in the 2016 and 2017 images demonstrate how researchers focused more on realistic tasks:
- Online
- Online, incremental setting for building recommendation model
- Online services
- Group
- Group recommendation
- Review
- Product
- Data from real-world services such as e-commerce
Of course, we cannot conclude by just using the limited amount of data, and some actual trends are very similar to the field of machine learning e.g., deep learning for recommender systems. However, at the same time, I strongly believe that recommender research focuses more and more on realistic scenarios in the future as the word cloud illustrates.
Data for the highly practical applications always comes from a wide variety of real-world user-item interactions, and it is not limited to ratings on a 2-dimensional matrix.
Support
Gift a cup of coffeeCategories
Engineering Recommender Systems
See also
- October 14, 2022
- Ethics in Recommendation Pipeline—A First Look at RecSys 2022 Papers
- October 5, 2021
- User-Centricity Matters: My Reading List from RecSys 2021
- July 15, 2021
- Reviewing Ethical Challenges in Recommender Systems
Author: Takuya Kitazawa
I am a product builder, mentor, and advocate for sustainable technology development with a decade of experience in AI/ML products, data systems, and digital transformation. Based in Canada and originally from Japan, I have lived and worked globally, including part-time residence in Malawi, Africa. Visit my portfolio to learn more about my work, or reach out to me at [email protected].
NowDisclaimer
- Opinions are my own and do not represent the views of organizations I am/was belonging to.
- I use Grammarly for correcting grammatical errors, but I do not rely on any other generative AI tools to create my blog content.
- I am doing my best to ensure the accuracy and fair use of the information. However, there might be some errors, outdated information, or biased subjective statements due to the nature of a personal website. Visitors understand the limitations and rely on any information at their own risk.
- If there are any issues with the content, please contact me so I can take the necessary action.